This is the 21st edition of the Haskell Communities and Activities Report.
As usual, fresh entries are formatted using a blue background, while updated entries have a header with a blue background.
Entries for which I received a liveness ping, but which have seen no essential update for a while, have been replaced with online pointers to previous versions.
Other entries on which no new activity has been reported for a year or longer have been dropped completely.
Please do revive such entries next time if you do have news on them.
A call for new entries and updates to existing ones will be issued on the usual mailing lists in April.
Now enjoy the current report and see what other Haskellers have been up to lately.
Any feedback is
very welcome, as always.
TODO: Persistent library — Improving the DSH library is my current preference.
The principle of this library is KISS, and "don’t reinvent the wheel" by reusing existing state-of-the-art libraries.
For the example code listed above, please refer to https://github.com/lilac/ivy-example/
Recent developments
I have ported ivy-web from wai to snap-server backend, and also wrote a sample project correspond to the starter project of snap.
When everything is fine and I am free, I will upload the code and bump the version to 0.2.
Further reading
rss2irc is an IRC bot that polls a single RSS or Atom feed and announces
new items to an IRC channel, with options for customizing output and
behavior. It aims to be an easy to use, dependable bot that does its job
and creates no problems.
rss2irc was published in 2008 by Don Stewart. Simon Michael took over
maintainership in 2009, with the goal of making a robust low-maintenance
bot to stimulate development in various free/open-source software
communities. It is currently used for several full-time bots including:
- hackagebot — announces new hackage releases in #haskell
- hledgerbot — announces hledger commits in #ledger
- zwikicommitbot — announces Zwiki commits in #zwiki
- squeaksobot — announces Squeak and Smalltalk-related Stack Overflow questions in #squeak
- squeakquorabot — announces Squeak/Smalltalk-related Quora questions in #squeak
- etoystrackerbot — announces new Etoys bugs in #etoys
- etoysupdatesbot — announces Etoys commits in #etoys
- planetzopebot — announces new planet.zope.org posts in #zope
The project is available under BSD license from its home page at
http://hackage.haskell.org/package/rss2irc.
Since last report there has been a great deal of cleanup and
enhancement, but no new release on hackage yet due to an xml-related
memory leak.
Further reading
http://hackage.haskell.org/package/rss2irc
5.3 Haskell and Games
FunGEn (Functional Game Engine) is a BSD-licensed cross-platform 2D
game engine implemented in and for Haskell, using OpenGL and GLUT. It
was created in 2002 by Andre Furtado, updated in 2008 by Simon Michael
and Miloslav Raus, and revived again in 2011, with a GHC 6.12-tested
0.3 release on Hackage, preliminary haddockification and a new home
repo.
FunGEn remains the quickest path to building cross-platform graphical
games in Haskell, due to its convenient game framework and
widely-available dependencies. It comes with several working examples
that are quite easy to read and build (pong, worms). In the last six
months there has been little activity and a new maintainer would be
welcome.
FunGEn-related discussions most often appear in the #haskell-game
channel on irc.freenode.net.
Further reading
http://darcsden.com/simon/fungen
5.3.2 Nikki and the Robots

Nikki and the Robots is a 2D platformer written in Haskell and produced by Joyride Laboratories. Nikki, the protagonist, walks and jumps around the levels wearing a cute ninja/cat costume. Nikki refrains from using any tools or weapons, with one exception: The Robots. These come in various types with different abilities and can be used by Nikki to solve puzzles, overcome obstacles, and complete the level tasks. The game features an integrated level editor.
We made our first binary release of Nikki and the Robots in April 2011.
Publishing
We are releasing the game and the level editor under an open source license (LGPL). The included graphics are published under a permissive Creative Commons license (cc-by-sa). We are also planning to create a server that will allow players to upload the levels they created and download levels from other players. We hope that a community of coders, level creators, and players will emerge around the game.
Simultaneously, we are working on episodes that we plan to sell via the game. These will include new graphics, more robots, a story line, other characters, and other surprises.
(Just to clarify: The licensing is very permissive. It allows others to create their own episodes and distribute them freely or sell them. This would be very welcome. If anybody is interested in this, we propose to join forces and sell all our episodes through one system.)
Technologies Used
- Qt for user input and rendering.
- OpenGL as an efficient rendering backend for Qt. Everything will remain 2D, though - we promise!
- Hipmunk, the Haskell bindings to the chipmunk physics engine.
Getting Involved
The project is still in alpha stage, so there are some features that are not yet implemented. For some, we have a clear vision on how to implement them; for others, we do not. If you want to get involved, check out our darcs repo, our launchpad site, and do not hesitate to contact us.
Further reading
5.4 Haskell and Compiler Writing
UUAG is the Utrecht University Attribute Grammar system. It is a preprocessor for Haskell
that makes it easy to write catamorphisms, i.e., functions that do to any data type what
foldr does to lists. Tree walks are defined using the intuitive concepts of
inherited and synthesized attributes, while keeping the full expressive power
of Haskell. The generated tree walks are efficient in both space and time.
An AG program is a collection of rules, which are pure Haskell functions between attributes.
Idiomatic tree computations are neatly expressed in terms of copy, default, and collection rules.
Attributes themselves can masquerade as subtrees and be analyzed accordingly (higher-order attribute). The order in which to visit the tree is derived automatically from the attribute computations. The tree walk is a single traversal from the perspective of the programmer.
Nonterminals (data types), productions (data constructors), attributes, and rules for attributes can be specified separately, and are woven and ordered automatically. These aspect-oriented programming features make AGs convenient to use in large projects.
The system is in use by a variety of large and small projects, such as the Utrecht Haskell Compiler UHC (→3.3), the editor Proxima for structured documents (http://www.haskell.org/communities/05-2010/html/report.html#sect6.4.5), the Helium compiler (http://www.haskell.org/communities/05-2009/html/report.html#sect2.3), the Generic Haskell compiler, UUAG itself, and many master student projects.
The current version is 0.9.39 (October 2011), is extensively tested, and is available on Hackage.
Recently, we improved the Cabal support and ensured compatibility with GHC 7.
We are working on the following enhancements of the UUAG system:
-
First-class AGs
-
We provide a translation from UUAG to AspectAG (→5.4.2).
AspectAG is a library of strongly typed Attribute Grammars
implemented using type-level programming. With this extension, we can write the main part of
an AG conveniently with UUAG, and use AspectAG for (dynamic) extensions. Our goal is to have
an extensible version of the UHC.
-
Ordered evaluation
-
We have implemented a variant of Kennedy and Warren (1976)
for ordered AGs. For any absolutely non-circular AGs, this algorithm finds a static
evaluation order, which solves some of the problems we had with an earlier approach for
ordered AGs. A static evaluation order allows the generated code to be strict, which is
important to reduce the memory usage when dealing with large ASTs.
The generated code is purely functional, does not require type
annotations for local attributes, and the Haskell compiler proves that the static evaluation
order is correct.
-
Multi-core evaluation
-
Our algorithm for ordered AGs identifies statically which subcomputations of children of a
production are independent and suitable for parallel evaluation. Together with the
strict evaluation as mentioned above, which is important when evaluating in parallel, the
generated code can automatically exploit multi-core CPUs. We are currently evaluating the
effectiveness of this approach.
-
Stepwise evaluation
-
In the recent past we worked on a stepwise evaluation scheme for AGs.
Using this scheme, the evaluation of a node may
yield user-defined progress reports, and the evaluation to the next report is
considered to be an evaluation step. By asking nodes to yield reports, we can encode
the parallel exploration of trees and encode breadth-first search strategies.
We are currently also running a Ph.D. project that investigates incremental evaluation.
Further reading
AspectAG is a library of strongly typed Attribute Grammars implemented using type-level programming.
Introduction
Attribute Grammars (AGs), a general-purpose formalism for describing recursive computations over data types,
avoid the trade-off which arises when building software incrementally:
should it be easy to add new data types and data type alternatives or to add new operations on existing data types?
However, AGs are usually implemented as a pre-processor,
leaving e.g. type checking to later processing phases and making interactive development,
proper error reporting and debugging difficult.
Embedding AG into Haskell as a combinator library solves these problems.
Previous attempts at embedding AGs as a domain-specific language were based on extensible records and thus exploiting
Haskell’s type system to check the well-formedness of the AG,
but fell short in compactness and the possibility to abstract over oft occurring AG patterns.
Other attempts used a very generic mapping for which the AG well-formedness could not be statically checked.
We present a typed embedding of AG in Haskell satisfying all these requirements.
The key lies in using HList-like typed heterogeneous collections (extensible polymorphic records)
and expressing AG well-formedness conditions as type-level predicates (i.e., typeclass constraints).
By further type-level programming we can also express common programming patterns,
corresponding to the typical use cases of monads such as Reader, Writer, and State.
The paper presents a realistic example of type-class-based type-level programming in Haskell.
We have included support for local and higher-order attributes.
Furthermore, a translation from UUAG to AspectAG is added to UUAGC as an experimental feature.
Current Status
We have recently added a combinator agMacro to provide support
for “attribute grammars macros”; a mechanism that makes it easy to
define attribute computation in terms of already existing attribute computation.
Background
The approach taken in AspectAG was proposed by Marcos Viera,
Doaitse Swierstra, and Wouter Swierstra in the
ICFP 2009 paper
“Attribute Grammars Fly First-Class: How to do aspect oriented programming in Haskell”.
The Attribute Grammar Macros combinator is described in a technical report:
UU-CS-2011-028.
Further reading
http://www.cs.uu.nl/wiki/bin/view/Center/AspectAG
6 Development Tools
6.1 Environments
EclipseFP is a set of Eclipse plugins to allow working on Haskell code projects.
It features Cabal integration (.cabal file editor, uses Cabal settings for compilation), and GHC integration. Compilation is done via the GHC API, syntax coloring uses the GHC Lexer. Other standard Eclipse features like code outline, folding, and quick fixes for common errors are also provided. EclipseFP also allows launching GHCi sessions on any module including extensive debugging facilities. It uses Scion to bridge between the Java code for Eclipse and the Haskell APIs.
The source code is fully open source (Eclipse License) and anyone can contribute. Current version is 2.1.0, released in September 2011 and supporting GHC 6.12 and 7.0, and more versions with additional features are planned. Feedback on what is needed is welcome! The website has information on downloading binary releases and getting a copy of the source code. Support and bug tracking is handled through Sourceforge forums.
Further reading
http://eclipsefp.sourceforge.net/
6.1.2 ghc-mod — Happy Haskell Programming on Emacs
ghc-mod is an enhancement of the Haskell mode on Emacs. It provides the following features:
-
Completion
-
You can complete a name of keyword, module, class, function, types, language extensions, etc.
-
Code template
-
You can insert a code template according to the position of the cursor. For instance, “module Foo where” is inserted in the beginning of a buffer.
-
Syntax check
-
Code lines with error messages are automatically highlighted thanks to flymake. You can display the error message of the current line in another window. hlint (→6.3.2) can be used instead of GHC to check Haskell syntax.
-
Document browsing
-
You can browse the module document of the current line either locally or on Hackage.
-
Function type
-
You can display the type/information of the function on the cursor. (new)
ghc-mod consists of code in Emacs Lisp and a sub-command in Haskell.
The Emacs code executes the sub-command to obtain information about
your Haskell environment. The sub-command makes use of the GHC API
for that purpose.
ghc-mod now supports “hs-source-dirs” in a cabal file and GHC 7.2.
Further reading
http://www.mew.org/~kazu/proj/ghc-mod/en/
6.1.3 Leksah — The Haskell IDE in Haskell
Leksah is a Haskell IDE written in Haskell. It is still beta quality,
but we hope we can publish the 1.0 release this year.
The project has its focus on providing a practical tool for Haskell
development.
Leksah has already proved its usefulness in industrial projects.
We have had positive feedback and are pleased to see that a large number
of people are downloading Leksah and we hope you are finding it useful.
Leksah is at a critical point in its development, as it is difficult
to bring a project of this size to a success, considering we are just
two developers which work on it in their rare spare time.
If you can spare some time to work on part of the project, please get in
touch
by mailing the Leksah group or log onto IRC #leksah.
If there is something you do not like about Leksah let us know
and we can probably show you where to get started
fixing it.
We believe that Leksah can be an important contribution for Haskell,
to make its way from an academic language to a valuable tool in
industry.
Further reading
http://leksah.org/
6.1.5 HaRe — The Haskell Refactorer
Refactorings are source-to-source program transformations which change
program
structure and organization, but not program functionality. Documented in
catalogs and supported by tools, refactoring provides the means to adapt and
improve the design of existing code, and has thus enabled the trend towards
modern agile software development processes.
Our project, Refactoring Functional Programs, has as its major
goal to
build a tool to support refactorings in Haskell. The HaRe tool is now in its
sixth major release. HaRe supports full Haskell 98, and is integrated
with (X)Emacs and Vim. All the refactorings that HaRe supports, including
renaming, scope change, generalization and a number of others, are
module-aware, so that a change will be reflected in all the modules in a project,
rather than just in the module where the change is initiated. The system
also
contains a set of data-oriented refactorings which together transform a
concrete data type and associated uses of pattern matching into an
abstract type and calls to assorted functions. The latest snapshots
support the
hierarchical modules extension, but only small parts of the hierarchical
libraries, unfortunately.
In order to allow users to extend HaRe themselves,
HaRe includes an API for users to define their own program
transformations, together with Haddock documentation.
Please let us know if you are using the API.
Snapshots of HaRe are available from our webpage, as are related
presentations and publications from the group (including LDTA’05, TFP’05, SCAM’06, PEPM’08, PEPM’10, TFP’10, Huiqing’s PhD thesis and Chris’s PhD thesis).
The final report for the project appears there, too.
Recent developments
- HaRe 0.6, which is compatible with GHC-6.12.1, has been released; HaRe 0.6 is available on Hackage, and also downloadable from our project webpage.
- HaRe 0.6 comes with a number of new refactorings, including adding and
removing fields and constructors to data-type definitions, folding and unfolding against as-patterns, merging and splitting function definitions, converting between let and where constructs, introducing pattern matching and
generative folding.
- Support for automatic detection and semi-automatic elimination of duplicated code in Haskell programs is also available from HaRe 0.6.
- Support for a number of new refactorings for parallel Haskell have recently been added to HaRe. These include support to introduce simple divide and conquer parallelism, using the new Strategies module. The refactorings are designed to issue warnings to the user when ill-defined evaluation degrees are set, together with support for adding a threshold value.
Further reading
http://www.cs.kent.ac.uk/projects/refactor-fp/
6.2 Documentation
Haddock is a widely used documentation-generation tool for Haskell
library code. Haddock generates documentation by parsing and typechecking
Haskell source code directly and including documentation supplied by the
programmer in the form of specially-formatted comments in the source code
itself. Haddock has direct support in Cabal (→6.8.1), and is used to
generate the documentation for the hierarchical libraries that come with GHC,
Hugs, and nhc98
(http://www.haskell.org/ghc/docs/latest/html/libraries) as well as
the documentation on Hackage.
The latest release is version 2.9.4, released October 3 2011.
Recent changes:
- Support for GHC 7.2 and Alex 3.x
- New –qual flag for qualification of names
- Print doc coverage information to stdout
- Speed up generation of index
- Various bug fixes
Future plans
- Although Haddock understands many GHC language extensions, we would like it to
understand all of them. Currently there are some constructs you cannot comment,
like GADTs and associated type synonyms.
- Error messages is an area with room for improvement. We would like Haddock
to include accurate line numbers in markup syntax errors.
- On the HTML rendering side we want to make more use of Javascript in order to make
the viewing experience better. The frames-mode could be improved this way, for
example.
- Finally, the long term plan is to split Haddock into one program that creates
data from sources, and separate backend programs that use that data via the
Haddock API. This will scale better, not requiring adding new backends to Haddock
for every tool that needs its own format.
Further reading
Hoogle is an online Haskell API search engine. It searches the functions in the various libraries,
both by name and by type signature. When searching by name, the search just finds functions which
contain that name as a substring. However, when searching by types it attempts to find any functions
that might be appropriate, including argument reordering and missing arguments. The tool is written
in Haskell, and the source code is available online. Hoogle is available as a web interface, a
command line tool, and a lambdabot plugin.
Hoogle has seen significant revisions in the last few months. Hoogle can now search all of Hackage (→6.8.1),
and has a brand new look and feel, including instant results as you type. Work continues improving
the performance and quality of the results.
Further reading
http://haskell.org/hoogle
This tool by Ralf Hinze and Andres Löh
is a preprocessor that transforms literate Haskell or Agda
code into LaTeX documents. The output is highly customizable
by means of formatting directives that are interpreted
by lhs2TeX. Other directives allow the selective inclusion
of program fragments, so that multiple versions of a program
and/or document can be produced from a common source.
The input is parsed using a liberal parser that can interpret
many languages with a Haskell-like syntax.
The program is stable and can take on large documents.
The current version is 1.17, so there has not been a new release
since the last report. Development repository and bug tracker
are on GitHub. There are still plans for a rewrite of lhs2TeX
with the goal of cleaning up the internals and making the functionality of
lhs2TeX available as a library.
Further reading
6.3 Testing and Analysis
shelltestrunner was first released in 2009, inspired by the test suite
in John Wiegley’s ledger project. It is a command-line tool for doing
repeatable functional testing of command-line programs or shell
commands. It reads simple declarative tests specifying a command, some
input, and the expected output, error output and exit status. Tests
can be run selectively, in parallel, with a timeout, in color, and/or
with differences highlighted.
In the last six months, shelltestrunner has had three releases (1.0,
1.1, 1.2) and acquired a home page. Projects using it include hledger,
yesod, berp, and eddie. shelltestrunner is free software released
under GPLv3+ from Hackage or http://joyful.com/shelltestrunner.
Further reading
http://joyful.com/repos/shelltestrunner
HLint is a tool that reads Haskell code and suggests changes to make it simpler.
For example, if you call maybe foo id it will suggest using fromMaybe foo instead.
HLint is compatible with almost all Haskell extensions, and can be easily extended with additional hints.
There have been numerous feature improvements since the last HCAR, including features to
detect duplicated code within a module. HLint can be tried online within hpaste.org.
Further reading
http://community.haskell.org/~ndm/hlint/
This project was born during the 2009 Google Summer of Code under the
name “Improving space profiling experience”. The name
hp2any covers a set of tools and libraries to deal with heap
profiles of Haskell programs. At the present moment, the project
consists of three packages:
- hp2any-core: a library offering functions to read heap
profiles during and after run, and to perform queries on them.
- hp2any-graph: an OpenGL-based live grapher that can
show the memory usage of local and remote processes (the latter
using a relay server included in the package), and a library
exposing the graphing functionality to other applications.
- hp2any-manager: a GTK application that can display
graphs of several heap profiles from earlier runs.
The project also aims at replacing hp2ps by reimplementing it
in Haskell and possibly adding new output formats. The manager
application shall be extended to display and compare the graphs in
more ways, to export them in other formats and also to support live
profiling right away instead of delegating that task to
hp2any-graph.
Recently, the hp2any project joined forces with
hp2pretty, which resulted in increased performance in the
core library.
Further reading
6.4 Optimization
HFusion is an experimental tool for optimizing Haskell programs.
The tool performs source to source transformations by the application of a program
transformation technique called fusion. The aim of fusion is to reduce
memory management effort by eliminating the intermediate data structures produced
in function compositions.
It is based on an algebraic approach where functions are internally represented
in terms of a recursive program scheme known as hylomorphism.
We offer a web interface to test the technique on user-supplied recursive definitions and
HFusion is also available as a library on Hackage.
The last improvement to HFusion has been to accept as input an expression containing any number
of compositions, returning the expression which results from applying fusion to all of them.
Compositions which cannot be handled by HFusion are left unmodified.
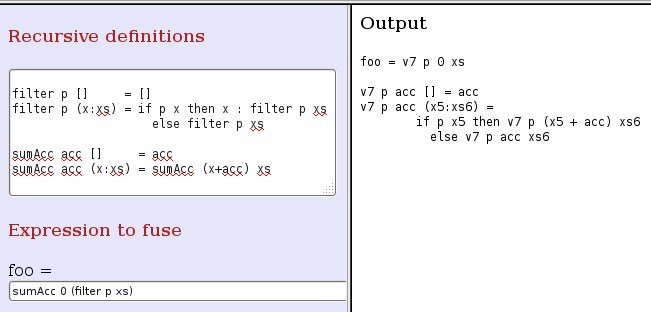
In its current state, HFusion is able to fuse compositions of general recursive functions,
including primitive recursive functions (like dropWhile or insertions in binary search trees),
functions that make recursion over multiple arguments like zip, zipWith or equality predicates,
mutually recursive functions, and (with some limitations) functions with accumulators like foldl.
In general, HFusion is able to eliminate intermediate data structures of regular data types
(sum-of-product types plus different forms of generalized trees).
Further reading
6.4.2 Optimizing Generic Functions
Datatype-generic programming increases program reliability by reducing code
duplication and enhancing reusability and modularity. Several generic
programming libraries for Haskell have been developed in the past few years.
These libraries have been compared in detail with respect to expressiveness,
extensibility, typing issues, etc., but performance comparisons have been brief,
limited, and preliminary. It is widely believed that generic programs run slower
than hand-written code.
At Utrecht University we are looking into the performance of different generic
programming libraries and how to optimize them. We have confirmed that generic
programs, when compiled with the standard optimization flags of the Glasgow
Haskell Compiler (GHC), are substantially slower than their hand-written
counterparts.
However, we have also found that advanced optimization capabilities of GHC,
such as inline pragmas and rewrite rules, can be used to further optimize
generic functions, often achieving the same efficiency as hand-written code.
We are continuing our research in this topic and hope to provide more
information in the near future.
Further reading
http://dreixel.net/research/pdf/ogie.pdf
6.5 Boilerplate Removal
6.5.1 A Generic Deriving Mechanism for Haskell
Haskell’s deriving mechanism supports the automatic generation of instances for
a number of functions. The Haskell 98 Report only specifies how to generate
instances for the Eq, Ord, Enum, Bounded, Show, and Read classes. The
description of how to generate instances is largely informal. As a consequence,
the portability of instances across different compilers is not guaranteed.
Additionally, the generation of instances imposes restrictions on the shape of
datatypes, depending on the particular class to derive.
We have developed a new approach to Haskell’s deriving mechanism, which allows
users to specify how to derive arbitrary class instances using standard
datatype-generic programming techniques. Generic functions, including the
methods from six standard Haskell 98 derivable classes, can be specified
entirely within Haskell, making them more
lightweight and portable.
We have implemented our deriving mechanism together with many new derivable
classes in UHC (→3.3) and
GHC.
The implementation in GHC has a more convenient syntax; consider enumeration:
class GEnum a where
genum :: [a]
default genum :: ( Representable a,
Enum' (Rep a))
=> [a]
genum = map to enum'
instance (GEnum a) => GEnum (Maybe a)
instance (GEnum a) => GEnum [a]
These instances are empty, and therefore use the (generic) default
implementation. This is as convenient as writing |deriving| clauses, but allows
defining more generic classes.
This implementation relies on the new functionality of
default signatures,
like in |genum| above, which are like standard default methods but allow for a
different type signature.
Further reading
http://www.haskell.org/haskellwiki/Generics
6.6 Code Management
Darcs is a distributed revision control system written in Haskell. In
Darcs, every copy of your source code is a full repository, which allows for
full operation in a disconnected environment, and also allows anyone with
read access to a Darcs repository to easily create their own branch and
modify it with the full power of Darcs’ revision control. Darcs is based on
an underlying theory of patches, which allows for safe reordering and
merging of patches even in complex scenarios. For all its power, Darcs
remains a very easy to use tool for every day use because it follows the
principle of keeping simple things simple.
Our most recent release, Darcs 2.5.2, was in March 2011. The Darcs
2.5.x line provides faster repository-local operations, and faster
record with long patch histories, among other bug fixes and features.
The most recent version adds compatibility with Haskell Platform
2011.2.0.0.
We are currently working on releasing Darcs 2.8, which will include
Alexey Levan’s 2010 Google Summer of Code work on optimised darcs get
(using the “optimize –http” command) and a few refinements to Adolfo
Builes’ cache reliability work. The Darcs 2.8 release is planned to
include a faster and more human-readable annotate command.
Meanwhile, we are happy to have been able to participate in the Google
Summer of Code 2011 (as part of Haskell.org). We had two projects this
year, one to develop a a bidirectional bridge between Darcs and Git (and
potentially other VCSs), and the other to do some new exploratory work
on primitive patch types for a future Darcs 3. The bridge project will
improve collaboration between Darcs and Git users, allowing each to
contribute to projects hosted in the other’s VCS of choice. The
primitive patches work will allow us to implement some ideas we have
been discussing in the Darcs team in recent months, in particular,
separation of file dentifiers from file names and the separation of
on-disk patch contents from their in-memory representation. Making a
prototype implementation of these ideas will give us a better idea how
feasible they are in practice and help us to identify the technical
difficulities that may be lurking around the corner. Both projects
were succesful; see below for their respective wrap-ups and prototypes.
Darcs is free software licensed under the GNU GPL (version 2 or
greater). Darcs is a proud
member of the Software Freedom Conservancy, a US tax-exempt 501(c)(3)
organization. We accept donations at
http://darcs.net/donations.html.
Further reading
http://darcsden.com is a free Darcs (→6.6.1) repository
hosting service, similar to patch-tag.com or (in essence)
github. The darcsden software is also available (on darcsden)
so that anyone can set up a similar service. darcsden is available
under BSD license and was created by Alex Suraci.
Alex keeps the service running and fixes bugs, but is mostly focussed
on other projects. darcsden has a clean UI and codebase and is a
viable hosting option for smaller projects despite occasional
glitches.
The last Hackage release was in 2010. Other committers have been
submitting patches, and the darcsden software is close to becoming a
just-works installable darcs web ui for general use.
Further reading
http://darcsden.com
darcsum is an emacs add-on providing an efficient, pcl-cvs-like interface
for the Darcs revision control system (→6.6.1). It is especially useful for
reviewing and recording pending changes.
Simon Michael took over maintainership in 2010, and tried to make it more
robust with current Darcs. The tool remains slightly fragile, as it
depends on Darcs’ exact command-line output, and needs updating when that
changes. Dave Love has contributed a large number of cleanups.
darcsum is available under the GPL version 2 or later from
http://joyful.com/darcsum.
In the last six months darcsum acquired a home page, but there has
been little other activity. We are looking for a new maintainer for
this useful tool.
Further reading
http://joyful.com/darcsum/
6.6.6 cab — A Maintenance Command of Haskell Cabal Packages
cab is a MacPorts-like maintenance command of Haskell cabal packages. Some parts of this program are a wrapper to ghc-pkg, cabal, and cabal-dev.
If you are always confused due to inconsistency of ghc-pkg and cabal, or if you want a way to check all outdated packages, or if you want a way to remove outdated packages recursively, this command helps you.
cab now supports GHC 7.2.
Further reading
http://www.mew.org/~kazu/proj/cab/en/
Hackage-Debian is a tool for creating a Debian repository with all, or
almost all, of the packages in Hackage. It is highly based on the debian
available at http://hackage.haskell.org/package/debian. It should build
a snapshot of the Hackage database and then track each new package added to
build it on demand. It is still under development, but the first release
should be announced soon.
A limitation of the first version being developed is that it only builds the
latest version of each library. So, if a library depends on an older version
of another library, it will not be built. This is the reason why it does not
build all packages, but almost all of them.
Also, the first version will only deal with libraries, but there are plans to
also build programs.
The darcs repository for both hackage-debian and the modified version of the
debian package that it uses are available at
http://marcot.eti.br/darcs/hackage-debian and http://marcot.eti.br/darcs/haskell-debian.
6.7 Interfacing to other Languages
6.8 Deployment
Background
Cabal is the standard packaging system for Haskell software. It specifies a standard way in which Haskell libraries and applications can be packaged so that it is easy for consumers to use them, or re-package them, regardless of the Haskell implementation or installation platform.
Hackage is a distribution point for Cabal packages. It is an online archive of Cabal packages which can be used via the website and client-side software such as cabal-install. Hackage enables users to find, browse and download Cabal packages, plus view their API documentation.
cabal-install is the command line interface for the Cabal and Hackage system. It provides a command line program cabal which has sub-commands for installing and managing Haskell packages.
Recent progress
We have had two successful Google Summer of Code projects on Cabal this year. Sam Anklesaria worked on a “cabal repl” feature to launch an interactive GHCi session with all the appropriate pre-processing and context from the project’s .cabal file. Mikhail Glushenkov worked on a feature so that “cabal install” can build independent packages in parallel (not to be confused with building modules within a package in parallel). The code from both projects is available and they are awaiting integration into the main Cabal repository, which we expect to happen over the course of the next few months.
The “cabal test” feature which was developed as a GSoC project last summer has matured significantly in the last 6 months, thanks to continuing effort from Thomas Tuegel and Johan Tibell. The basic test interface will be ready to use in the next release, and there has been some progress on the “detailed” test interface.
The IHG is currently sponsoring some work on cabal-install. The first fruits of this work is a new dependency solver for cabal-install which is now included in the development version. The new solver can find solutions in more cases and produces more detailed error messages when it cannot find a solution. In addition, it is better about avoiding and warning about breaking existing installed packages. We also expect it to be a better basis for other features in future. For more details see the presentation by Andres Löh.
http://haskell.org/haskellwiki/HaskellImplementorsWorkshop/2011/Loeh
The last 6 months has seen significant progress on the new hackage-server implementation with help from many new volunteers, in particular Max Bolingbroke, but also several other people who helped at hackathons and subsequently. The IHG funded Well-Typed to improve package mirroring so that continuous nearly-live mirroring is now possible. We are also grateful to factis research GmbH who have kindly donated a VM to help the hackage developers test the new server code. We expect to do live mirroring and public beta testing using this server during the next few months.
Looking forward
Users are increasingly relying on hackage and cabal-install and are increasingly frustrated by dependency problems. Solutions to the variety of problems do exist. It will however take sustained effort to solve them. The good news is that there is the realistic prospect of the new hackage-server being ready in the not too distant future with features to help monitor and encourage package quality, and the recent work on cabal-install should reduce the frustration level somewhat.
The last 6 months has seen a good upswing in the number of volunteers spending their time on cabal and hackage, so much so that a clear bottleneck is patch review and integration bandwidth. A similar issue is that many of the long standing bugs and feature requests require significant refactoring work which many volunteers feel reluctant or unable to do. Assistance in these areas would be very valuable indeed.
We would like to encourage people considering contributing to join the cabal-devel mailing list so that we can increase development discussion and improve collaboration. The bug tracker is reasonably well maintained and it should be relatively clear to new contributors what is in need of attention and which tasks are considered relatively easy.
Further reading
7 Libraries
7.1 Processing Haskell
7.2 Parsing and Transforming
Library for parsing and manipulating ePub files and OPF package data. An attempt has been made here to very thoroughly implement the OPF Package Document specification.
epub-metadata is available from Hackage, the Darcs repository below, and also in binary form for Arch Linux through the AUR.
See also epub-tools (→8.8.10).
Further reading
7.2.3 Utrecht Parser Combinator Library: uu-parsinglib
The previous extension for recognizing merging parsers was generalized so now any kind of applicative and monadic parsers can be merged in an interleaved way. As an example take the situation where many different programs write log entries into a log file, and where each log entry is uniquely identified by a transaction number (or process number) which can be used to distinguish them. E.g., assume that each transaction consists of an |a|, a |b| and a |c| action, and that a digit is used to identify the individual actions belonging to the same transaction; the individual transactions can now be recognized by the parser:
pABC :: Grammar String
pABC = (\ a d -> d:a) <$> pA <*> (pDigit' >>=
\d -> pB *> mkGram (pSym d) *>
pC *> mkGram (pSym d)
)
run (pmMany(pABC)) "a2a1b1b2c2a3b3c1c3"
Result: ["2a","1a","3a"]
Furthermore the library was provided with many more examples in two modules in the |Demo| directory.
Features
-
Much simpler internals than the old library (http://haskell.org/communities/05-2009/html/report.html#sect5.5.8) .
-
Combinators for easily describing parsers which produce their results online, do not hang on to the input and provide excellent error messages. As such they are “surprise free” when used by people not fully aware of their internal workings.
- Parsers “correct” the input such that parsing can proceed when an erroneous input is encountered.
- The library basically provides the to be preferred applicative interface and a monadic interface where this is really needed (which is hardly ever).
- No need for try-like constructs which makes writing Parsec based parsers tricky.
- Scanners can be switched dynamically, so several different languages
can occur intertwined in a single input file.
- Parsers can be run in an interleaved way, thus generalizing the merging and permuting parsers into a single applicative interface. This makes it e.g. possible to deal with white space or comments in the input in a completely separate way, without having to think about this in the parser for the language at hand (provided of course that white space is not syntactically relevant).
Future plans
Since the part dealing with merging is relatively independent of the underlying parsing machinery we may split this off into a separate package. This will enable us also to make use of a different parsing engines when combining parsers in a much more dynamic way. In such cases we want to avoid too many static analyses.
Future versions will contain a check for grammars being not left-recursive, thus taking away the only remaining source of surprises when using parser combinator libraries. This makes the library even greater for use teaching environments. Future versions of the library, using even more abstract interpretation, will make use of computed look-ahead information to speed up the parsing process further.
The old library in the |uulib| package stays stable, and can continue to be used. A few changes were needed in order to make it compile with GHC 7.2.
Contact
If you are interested in using the current version of the library in order
to provide feedback on the provided interface, contact <doaitse at swierstra.net>. There is a low volume, moderated mailing list which was moved to <parsing at lists.science.uu.nl> (see also http://www.cs.uu.nl/wiki/bin/view/HUT/ParserCombinators).
7.2.4 Regular Expression Matching with Partial Derivatives
We are still improving the performance of our
matching algorithms. The latest implementation can be downloaded
via hackage.
Further reading
regex-applicative is aimed to be an efficient and easy to use parsing combinator library for Haskell based on regular expressions.
Regular expressions have Perl-like (left-biased) semantics to satisfy most of
the daily regex needs, but also allow longest matching prefix search
useful for
lexical analysis.
For example, the following code finds filename extensions:
import Text.Regex.Applicative
getExtension :: String -> Maybe String
getExtension str =
str =~
many anySym *>
sym '.' *>
many anySym
More examples can be found on the
wiki.
Further reading
7.3 Mathematical Objects
7.3.1 normaldistribution: Minimum Fuss Normally Distributed Random Values
Normaldistribution is a new package that lets you produce normally
distributed random values with a minimum of fuss. The API builds
upon, and is largely analogous to, that of the Haskell 98 Random
module (more recently System.Random). Usage can be as simple as:
sample <-normalIO. For more information and examples see
the package description on Hackage.
Further reading
http://hackage.haskell.org/package/normaldistribution
7.3.2 dimensional: Statically Checked Physical Dimensions
Dimensional is a library providing data types for performing
arithmetics with physical quantities and units. Information about
the physical dimensions of the quantities/units is embedded in their
types, and the validity of operations is verified by the type checker
at compile time. The boxing and unboxing of numerical values as
quantities is done by multiplication and division with units. The
library is designed to, as far as is practical, enforce/encourage
best practices of unit usage within the frame of the si. Example:
d :: Fractional a => Time a -> Length a
d t = a / _2 * t ^ pos2
where a = 9.82 *~ (meter / second ^ pos2)
Ongoing experimental work includes:
The core library, dimensional, can be installed off Hackage using
cabal. The experimental packages can be cloned off of Github.
Dimensional relies on numtype for type-level integers (e.g., pos2 in the above example), ad for automatic differentiation,
and HList (→7.4.1) for type-level vector and matrix representations.
Further reading
7.3.3 AERN-Real and Friends
AERN stands for Approximating Exact Real Numbers.
We are developing a family of libraries that will provide:
-
a reliable and fast arbitrary precision
correctly rounded interval arithmetic, including
both standard and inverted intervals with Kaucher arithmetic
-
arbitrary precision arithmetic of interval polynomials
and polynomial intervals to
-
automatically reduce overestimations in interval computations
-
efficiently support validated numerical integration
-
automatically decide many inequalities and interval inclusions
with non-linear and elementary functions
that occur in numerical theorem proving and specifically
in the verification of numerical programs
-
a type class hierarchy for validated
and exact computation, featuring
-
standard mathematical structures
such as posets and lattices extended to
take account of rounding errors and
partially decided relations such as equality
-
separate treatment of numerical order and
interval refinement order
-
ability to increase computational effort to reduce
the effect of rounding and partiality,
converging to no rounding and total relations
with infinite effort
-
extensive set of QuickCheck properties for each
type class, enabling automatic checking of, e.g.,
algebraic properties such as associativity
extended to take account of rounding
-
a framework for distributed query-driven lazy dataflow
exact numerical computation with tidy
exact semantics based on Domain Theory
There are stable older versions of the libraries
on Hackage but these lack the type classes described above.
We are currently in the process of redesigning and rewriting the libraries
from scratch.
Out of the newly designed code we recently released libraries
featuring
- the type classes for approximate real number operations
- correctly rounded real interval arithmetic with Double endpoints
A release of interval arithmetic with MPFR endpoints is planned as soon as
a solution is found for an easier installation of the hmpfr package.
(Currently one has to compile a ghc without gmp to use hmpfr.)
We have made progress on implementing polynomial intervals
with a core written in C but have suspended the development until
we finish a Haskell-only implementation of an arithmetic of interval polynomials
(ie polynomials with interval coefficients).
We are likely to use interval polynomials as endpoints for
polynomial intervals when the work on polynomial intervals is resumed.
The development files now include demos that apply interval polynomials
on validated simulation of selected ODE IVPs and hybrid systems.
All AERN development is open and we welcome contributions and
new developers.
Further reading
http://code.google.com/p/aern/
Paraiso is a domain-specific language (DSL) embedded in Haskell, aimed
at generating explicit type of partial differential equations solving
programs, for accelerated and/or distributed computers. Equations for
fluids, plasma, general relativity, and many more falls into this
category. This is still a tiny domain for a computer scientist, but
large enough that an astrophysicist (I am) might spend even his entire
life in it.
In Paraiso we can describe equation-solving algorithms in
mathematical, simple notation using builder monads. At the
moment it can generate programs for multicore CPUs as well as single
GPU, and tune their performance via automated benchmarking and genetic
algorithms. The experiment is under way; the fluid simulator I am using
is 464 lines in Haskell. So far, Paraiso has tried more than
117’000 different implementations of this single algorithm, each being
about 10’000 lines of CUDA program. The best one found so far is 33.4
times faster than the initial guess, and twice faster than the
hand-tuned implementation.
Anyone can get Paraiso from hackage
(http://hackage.haskell.org/package/Paraiso) or github
(https://github.com/nushio3/Paraiso).
The next big challenge is to make Paraiso generate distributed
computations.
Further reading
http://paraiso-lang.org/wiki/
7.4 Data Types and Data Structures
7.4.1 HList — A Library for Typed Heterogeneous Collections
HList is a comprehensive, general purpose Haskell library for typed
heterogeneous collections including extensible polymorphic records and
variants. HList is analogous to the standard list
library, providing a host of various construction, look-up, filtering,
and iteration primitives. In contrast to the regular lists, elements
of heterogeneous lists do not have to have the same type. HList lets
the user formulate statically checkable constraints: for example, no
two elements of a collection may have the same type (so the elements
can be unambiguously indexed by their type).
An immediate application of HLists is the implementation of open,
extensible records with first-class, reusable, and compile-time only
labels. The dual application is extensible polymorphic variants (open
unions). HList contains several implementations of open records,
including records as sequences of field values, where the type of each
field is annotated with its phantom label. We and others have also used
HList for type-safe database access in Haskell. HList-based Records
form the basis of OOHaskell. The HList library relies on common
extensions of Haskell 2010. HList is being used in AspectAG
(→5.4.2), typed EDSL of attribute grammars, and in HaskellDB.
The October 2011 version of HList library has many changes, mainly related to
deprecating TypeCast (in favor of ~) and getting rid
of overlapping instances. The only use of OverlappingInstances is in
the implementation of the generic type equality predicate
TypeEq. We plan to remove even that remaining single
occurrence. The code works with GHC 7.0.4.
Future plans include the implementation of TypeEq without resorting to
overlapping instances (so, HList will be overlapping-free), and moving
towards type functions and expressive kinds.
Further reading
Persistent is a type-safe data store interface for Haskell.
Haskell has many different database bindings available. However, most
of these have little knowledge of a schema and therefore do not provide
useful static guarantees. They also force database-dependent interfaces and
data structures on the programmer.
There are Haskell specific data stores such as acid-state that get around these flaws.
This allows one to easily store any Haskell type and have type-safe interactions with data.
However, the use case is limited to in memory storage without replication,
and they aren’t designed to interface with other programming languages.
Persistent maintains much of the advantage of using native Haskell data types — you store and retrieve normal Haskell records, and your queries are also type-safe — they must match the schema. However, Persistent lets you persist your data to a battle tested database of your choice that is well optimized for your problem domain. Persistent is backend agnostic, and there are currently interfaces to Sqlite, Postgresql, and MongoDB.
Since the last report, Persistent has undergone an internal re-write and major API changes.
The MongoDB backend has been polished and works out of the box with the Yesod web framework.
Here is a quick example of the new Persistent query language:
selectList [ PersonFirstName ==. "Simon",
PersonLastName ==. "Jones"] []
Future plans
There are 3 main directions for Persistent:
- Improvements that work across all Persistent backends (example: better application-level
joins)
- Better database-specific integration (example: better SQL joins)
- Adding more database backends
Most of Persistent development occurs within the Yesod (→5.2.6) community.
However, there is nothing specific to Yesod about it.
You can have a type-safe, productive way to store data,
even on a project that has nothing to do with web development.
Further reading
http://yesodweb.com/book/persistent
7.5 Generic and Type-Level Programming
Unbound is a domain-specific language and library for working with
binding structure. Implemented on top of the RepLib generic
programming framework, it automatically provides operations such as
alpha equivalence, capture-avoiding substitution, and free variable
calculation for user-defined data types, requiring only a tiny bit of
boilerplate on the part of the user. It features a simple yet rich
combinator language for binding specifications, including support for
pattern binding, type annotations, recursive binding, nested binding,
and multiple atom types.
Since the last HCAR, a new version of Unbound has been released,
adding support for several set-like binding strategies (where the
order of bound variables does not matter) and for GADTs which do
not use existential quantification.
Further reading
A library of flexible newtype wrappers which simplify the process of
selecting appropriate typeclass instances,
which is particularly useful for composed types.
Version 0.1.0 has been released on Hackage,
providing support for a more comprehensive range of typeclasses
when wrapping simple values,
and some documentation.
Work is still ongoing to flesh out the typeclass instances available
and improve the documentation.
7.5.3 Generic Programming at Utrecht University
One of the research themes investigated within the
Software Technology Center in the
Department of Information and Computing Sciences at
Utrecht University is generic programming. Over the
last 15 years, we have played a central role in the development of generic
programming techniques, languages, and libraries.
Currently we maintain a number of
generic programming libraries and applications. We report most of them in
this entry; emgm was reported on before (http://haskell.org/communities/05-2009/html/report.html#sect5.9.3), and
our
generic deriving mechanism
has its own entry (→6.5.1).
-
multirec
-
This library represents datatypes uniformly and grants
access to sums (the choice between constructors), products (the sequence of
constructor arguments), and recursive positions. Families of mutually recursive
datatypes are supported. Functions such as map, fold,
show, and equality are provided as examples within the library. Using
the library functions on your own families of datatypes requires some
boilerplate code in order to instantiate the framework, but is facilitated by
the fact that multirec contains Template Haskell code that generates
these instantiations automatically.
The multirec library can also be used for type-indexed datatypes. As a
demonstration, the zipper library is
available on Hackage. With
this datatype-generic zipper, you can navigate values of several types.
The latest version
available on Hackage
includes limited support for datatype compositions; we are
still planning to extend the library with support for parameterized datatypes.
-
regular
-
While multirec focuses on support for mutually recursive regular
datatypes, regular supports only single regular datatypes. The approach
used is similar to that of multirec, namely using type families to
encode the pattern functor of the datatype to represent generically. There have
been no major releases of the
regular or
regular-extras packages on Hackage since the last report. The current
versions provide a number of typical generic functions, but also some less
well-known but useful functions: deep seq, QuickCheck’s
arbitrary and coarbitrary, and binary’s get
and put.
-
instant-generics
-
Using type families and type classes in a way similar to multirec and
regular, instant-generics is yet another approach to generic
programming, supporting a large variety of datatypes and allowing the definition
of type-indexed datatypes. It was first described by
Chakravarty et al.,
and forms the basis of one of our rewriting libaries. It is
available on Hackage.
-
syb
-
Scrap Your Boilerplate (syb) has been supported by GHC since the 6.0
release. This library is based on combinators and a few primitives for type-safe
casting and processing constructor applications. It was
originally developed by Ralf Lämmel and Simon Peyton Jones. Since then,
many people have contributed with research relating to syb or its
applications.
Since syb has been separated from the base package, it can now
be updated independently of GHC. We have recently released
version 0.3 on Hackage, which
has some minor extensions and fixes.
-
Annotations
-
We presented two applications of generic annotations at the Workshop
on Generic Programming 2010:
selections and
storage. In the
former we use annotations at every recursive position of a datatype to allow for
inserting position information automatically. This allows for informative
parsing error messages without the need for explicitly changing the datatype
to contain position information. In the latter we use the annotations as
pointers to locations in the heap, allowing for transparent and efficient
data structure persistency on disk.
-
Rewriting
-
We also maintain two libraries for generic rewriting: a
simple, earlier
library based on regular, and the
guarded
rewriting library, based on instant-generics. The former allows for
rewriting only on regular datatypes, while the latter supports more datatypes
and also rewriting rules with preconditions.
We also continue to look at benchmarking and improving the performance of
different libraries for generic programming (→6.4.2).
Further reading
http://www.cs.uu.nl/wiki/GenericProgramming
7.6 User Interfaces
Gtk2Hs is a set of Haskell bindings to many of the libraries included
in the Gtk+/Gnome platform. Gtk+ is an extensive and mature
multi-platform toolkit for creating graphical user interfaces.
GUIs written using Gtk2Hs use themes to resemble the native look on
Windows. Gtk is the toolkit used by Gnome, one of the two major GUI toolkits
on Linux. On Mac OS programs written using Gtk2Hs are run by Apple’s
X11 server but may also be linked against a native Aqua implementation
of Gtk.
Gtk2Hs features:
- Automatic memory management (unlike some other C/C++ GUI
libraries, Gtk+ provides proper support for garbage-collected languages)
- Unicode support
- High quality vector graphics using Cairo
- Extensive reference documentation
- An implementation of the “Haskell School of Expression” graphics
API
- Bindings to many other libraries that build on Gtk: gio, GConf,
GtkSourceView 2.0, glade, gstreamer, vte, webkit
In a heroic effort, Duncan Coutts has adjusted Gtk2Hs and its build system to
run with GHC 7.X compilers. A release 0.12.1 was the result of this effort
which, however, was only announced on the Gtk2Hs website. Since then a few but
important bugs have been fixed, amongst them one relating to slow Cairo
drawing. These bug fixes are now in the current 0.12.2 release.
Further reading
7.7 Graphics
Assimp is a set of bindings to the Assimp Open Asset Import Library. This library can import many different types of 3D models for use in graphics. The full list of formats is available at the project website (linked below) and at the git repo for the project. Assimp is being developed alongside the Cologne ray tracer (→8.4.5) but could be useful in any 3D graphics project.
Further reading
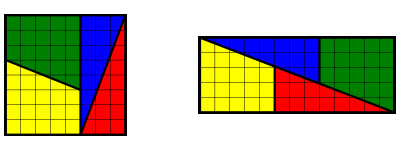
Craftwerk is a 2D vector graphic library. The motivation was to have a graphic library that is able to generate output which can be embedded into LaTeX as well as support for rendering with Cairo. Thus the library separates the graphic’s data structure from any context dependency and the aim is to support various drivers. Currently a driver for output with the TikZ package (http://sourceforge.net/projects/pgf/) for LaTeX is available. Using the additional craftwerk-cairo and craftwerk-gtk packages, direct rendering into PDF files or GTK widgets is possible. The craftwerk-gtk package also provides functions to generate simple user interfaces for interactive graphics.
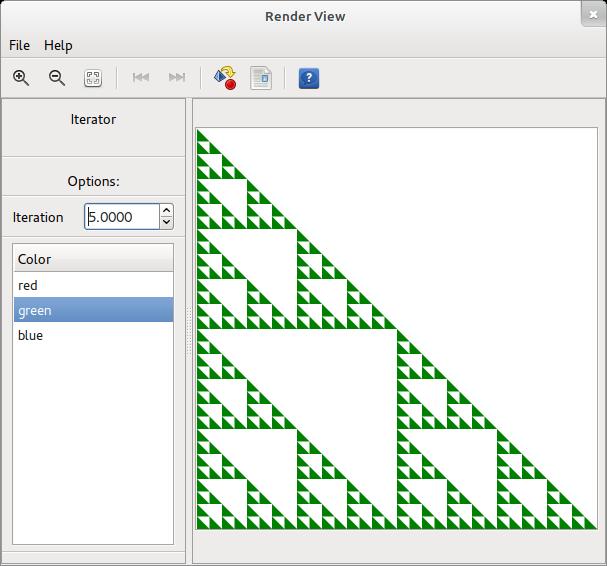
Above, two examples are shown.
In the first, you can see a screenshot of the GTK interface for interactive graphics showing a Sierpinski triangle, and the second is a simple example of a tree rendered with the Cairo driver. Graphics or figures can be created in a hierarchical fashion including the application of styles and decorations to subnodes. The current functionality includes almost the complete Cairo function set extended by arrow tips and a few primitives. The same function set is supported for TikZ output, and graphics generated with the two drivers match closely. Immediate development tasks are:
- Improvement of rendering speed in the Cairo driver.
- Better and unified text rendering capabilities.
- Refactoring of the UI module towards better usability.
Besides additional functionality, a long term goal is to support other drivers like Wumpus, Haha (ASCII rendering) or OpenGL. Craftwerk could also serve as an intermediate layer for libraries like plot or chart to enable LaTeX export. At the moment the library is still at a preliminary stage and the next step is a consolidation of a basic feature set. Any contributions or ideas are welcome and the latest code as well as experiments with other drivers are available on GitHub.
Further reading
LambdaCube is a 3D rendering engine entirely written in Haskell.
The main goal of this project is to provide a modern and feature rich
graphical backend for various Haskell projects, and in the long run it
is intended to be a practical solution even for serious purposes. The
engine uses Ogre3D’s (http://www.ogre3d.org) mesh and material
file format, therefore it should be easy to find or create new content
for it. The code sits between the low-level C API (raw OpenGL, DirectX
or anything equivalent; the engine core is graphics backend agnostic)
and the application, and gives the user a high-level API to work with.
The most important features are the following:
- loading and displaying Ogre3D models
- resource management
- modular architecture
If your system has OpenGL and GLUT installed, the
lambdacube-examples package should work out of the box. The
engine is also integrated with the Bullet physics engine (→8.8.7), and you can
find a running example in the lambdacube-bullet package.

Since the last update, the current version of the library saw only a
few minor updates: fast serialisation (using its own binary format)
and various bugfixes. Behind the scenes, we are working on a
completely new version, which will provide a graphics-oriented
data-flow DSL (in the same spirit as GPipe). The goal is to allow the
description of complex effects without mutable variables.
In the meantime, we also built a fully functional Stunts example,
which is available as a separate package.
Everyone is invited to contribute! You can help the project by playing
around with the code, thinking about API design, finding bugs (well,
there are a lot of them anyway), creating more content to display, and
generally stress testing the library as much as possible by using it
in your own projects.
Further reading
The diagrams library provides an embedded domain-specific language for
declarative drawing. The overall vision is for diagrams to become a
viable alternative to DSLs like MetaPost or Asymptote, but with the
advantages of being declarative—describing what to draw, not
how to draw it—and embedded—putting the entire power of
Haskell (and Hackage) at the service of diagram creation.
Development on the library has proceeded apace since the last HCAR,
and the 0.4 release now features a comprehensive user manual as well
as support for a large collection of primitive shapes, many different
modes of composition, paths, cubic splines, images, text, arbitrary
monoidal annotations, named subdiagrams, and more.
There is plenty more work to be done; new contributors are
particularly welcome!
Future plans
Plans for the near future include a native SVG backend, improved font
support, arrowheads, and improvements to the handling of named
subdiagrams. Longer-term plans include support for animations, a
custom Gtk application for editing diagrams, and any other awesome
stuff we think of.
Further reading
ChalkBoard is a domain specific language for describing images.
The language is uncompromisingly functional
and encourages the use of modern functional idioms.
The novel contribution of ChalkBoard is that it uses off-the-shelf
graphics cards to speed up rendering of our functional description.
We always intended to use ChalkBoard to animate educational
videos, as well as for processing streaming videos.
ChalkBoard also has an animation language,
based round an applicative functor, Active.
It has been called Functional Reactive Programming,
without the reactive part!
ChalkBoard has been released on hackage,
but is not actively being developed.
It would be nice to port the code to HTML5,
and we are happy to act as mentors for this effort.
Kevin Matlage graduated in May 2011 with an MS. His MS thesis was about the
design, implementation and applications of ChalkBoard. The thesis was awarded
the departmental Miller award, for best MS of the year.
Congratulations Kevin!
Further reading
http://www.ittc.ku.edu/csdl/fpg/Tools/ChalkBoard
7.8 Text and Markup Languages
Description
HaTeX is an implementation of LaTeX, with the aim to be
a helpful tool to generate LaTeX code.
From a global sight, it’s composed of:
- The LaTeX syntax description.
- A renderer of LaTeX code.
- A set of combinators of LaTeX entities.
- A monadic implementation of combinators.
- Methods for a subset of LaTeX packages.
What is new?
The third version of HaTeX has just released, and it is a completely
new implementation. Althought a lot of code is still valid, the
internal representation of values has changed drastically. Now,
the LaTeX code is written in an Abstract Syntax Tree (AST), via
the LaTeX datatype.
Future plans
A near future plan is to analyze the final AST output to find
possible errors in your LaTeX code, and to warn you about this.
Code is already adapting to this feature.
Other new coming features are tree draws from a tree data structure,
to extend the AMS-LaTeX functionality
(currently, too limited) and to implement a LaTeX code parser.
Contact
If you are someway interested in this project, please,
feel free to give any kind of opinion or idea,
or to ask any question you have. A good place
to take contact and stay tuned is the HaTeX mailing list:
hatex <at> projects.haskell.org
Of course, you always can mail to the maintainer.
Further reading
7.8.2 Haskell XML Toolbox
Description
The Haskell XML Toolbox (HXT) is a collection of tools for processing XML with
Haskell. It is itself purely written in Haskell 98. The core component of the
Haskell XML Toolbox is a validating XML-Parser that supports
almost fully the Extensible Markup Language (XML) 1.0 (Second Edition).
There is a validator based on DTDs and a new more powerful one for
Relax NG schemas.
The Haskell XML Toolbox is based on the ideas of HaXml and HXML,
but introduces a more general approach for processing XML with Haskell.
The processing model is based on arrows. The arrow interface is more flexible
than the filter approach taken in the earlier HXT versions and in HaXml.
It is also safer; type checking of combinators becomes possible with the arrow
approach.
HXT is partitioned into a collection of smaller packages: The core
package is
hxt. It contains a validating XML parser, an HTML parser,
filters for manipulating XML/HTML and so called XML pickler for
converting XML to and from native Haskell data.
Basic functionality for character handling and decoding is
separated into the packages hxt-charproperties and
hxt-unicode. These packages may be generally useful even for non XML projects.
HTTP access can be done with the help of the packages
hxt-http for native Haskell HTTP access and hxt-curl via a
libcurl binding. An alternative lazy non validating parser for XML and HTML can be
found in hxt-tagsoup.
The XPath interpreter is in package hxt-xpath, the XSLT part in
hxt-xslt
and the Relax NG validator in hxt-relaxng. For checking the XML
Schema Datatype definitions, also used with Relax NG, there is a
separate and generally useful regex package hxt-regex-xmlschema.
The old HXT approach working with filter hxt-filter is still
available,
but currently only with hxt-8. It has not (yet) been updated to the
hxt-9 mayor version.
Features
- Validating XML parser
- Very liberal HTML parser
- Lightweight lazy parser for XML/HTML based on Tagsoup (http://www.haskell.org/communities/05-2010/html/report.html#sect5.11.3)
- Binding to the expat parser via hexpat package
- Easy de-/serialization between native Haskell data and XML by pickler and pickler combinators
- XPath support
- Full Unicode support
- Support for XML namespaces
- Cabal package support for GHC
- HTTP access via Haskell bindings to libcurl and via Haskell HTTP
package
- Tested with W3C XML validation suite
- Example programs
- Relax NG schema validator
- Lightweight regex library with full support of Unicode and XML Schema
Datatype regular expression syntax
- An HXT Cookbook for using the toolbox and the arrow interface
- Basic XSLT support
- GitHub repository with current development versions of all packages
http://github.com/UweSchmidt/hxt
Current Work
In October 2011 a project has been started as part of a master thesis
for an XML validator based on XML Schema. Experiences with developing
the Relax-NG have shown, that such a project may be done within such a limited
time. The XML picklers can be used to easily parse XML Schema an transform it
into an AST. So the core work consists of developing an appropriate abstract
syntax and to normalize, check and transform this AST before validating XML documents.
Within this project the XML data type library already in use with Relax-NG is planned
to be completed. In the current version, time and date data types are not yet supported.
We expect to finish the work in March 2012.
Further reading
The Haskell XML Toolbox Web page
(http://www.fh-wedel.de/~si/HXmlToolbox/index.html)
includes links to downloads, documentation, and further information.
A getting started tutorial about HXT is available
in the Haskell Wiki (http://www.haskell.org/haskellwiki/HXT
). The conversion between XML and native Haskell data types is
described in another Wiki page
(http://www.haskell.org/haskellwiki/HXT/Conversion_of_Haskell_data_from/to_XML).
8 Applications and Projects
8.1 Education
8.1.1 Holmes, Plagiarism Detection for Haskell
Holmes is a tool for detecting plagiarism in Haskell programs.
A prototype implementation was made by Brian Vermeer under supervision
of Jurriaan Hage, in order to determine which heuristics work well.
This implementation could deal only with Helium programs.
We found that a token stream based comparison and Moss style fingerprinting
work well enough, if you remove template code and dead code before
the comparison. Since we compute the control flow graphs anyway,
we decided to also keep some form of similarity checking of control-flow
graphs (particularly, to be able to deal with certain refactorings).
In November 2010, Gerben Verburg started to reimplement Holmes keeping only
the heuristics we figured were useful, basing that implementation
on haskell-src-exts.
A large scale empirical validation has been made, and the results
are good. We have found quite a bit of plagiarism in a collection of about 2200
submissions, including a substantial number in which refactoring was
used to mask the plagiarism. A paper has been written, but is currently
unpublished.
The tool will not be made available
through Hackage, but will be available free of use to lecturers on request.
Please contact J.Hage@uu.nl for more information.
We also have a implemented graph based that computes
near graph-isomorphism that seems to work really well in comparing
control-flow graphs in an inexact fashion. However, it does not scale
well enough in terms of computations to be included in the comparison, and is
not mature enough to deal with certain easy refactorings.
Future work includes a Hare-against-Holmes bash in which Hare users will do
their utmost to fool Holmes.
8.1.2 Interactive Domain Reasoners
The Ideas project (at Open Universiteit Nederland and Universiteit
Utrecht) aims at developing interactive domain reasoners on various topics.
These reasoners assist students in solving exercises incrementally by checking
intermediate steps, providing feedback on how to continue, and detecting
common mistakes. The reasoners are based on a strategy language, from which
all feedback is derived automatically. The calculation of feedback is offered
as a set of web services, enabling external (mathematical) learning environments
to use our work. We currently have a binding with the Digital Mathematics
Environment (DWO) of the Freudenthal Institute, the ActiveMath learning
system (DFKI and Saarland University), and our own online exercise assistant
that supports rewriting logical expressions into disjunctive normal form.
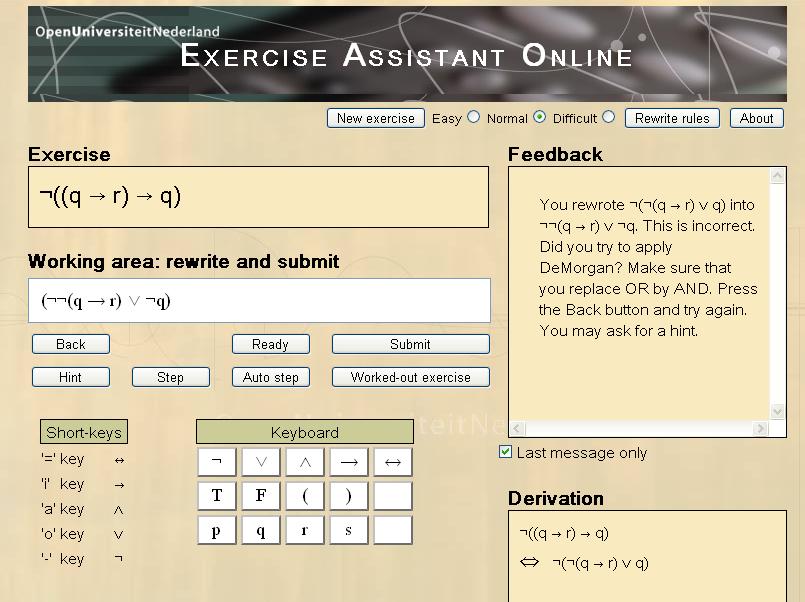
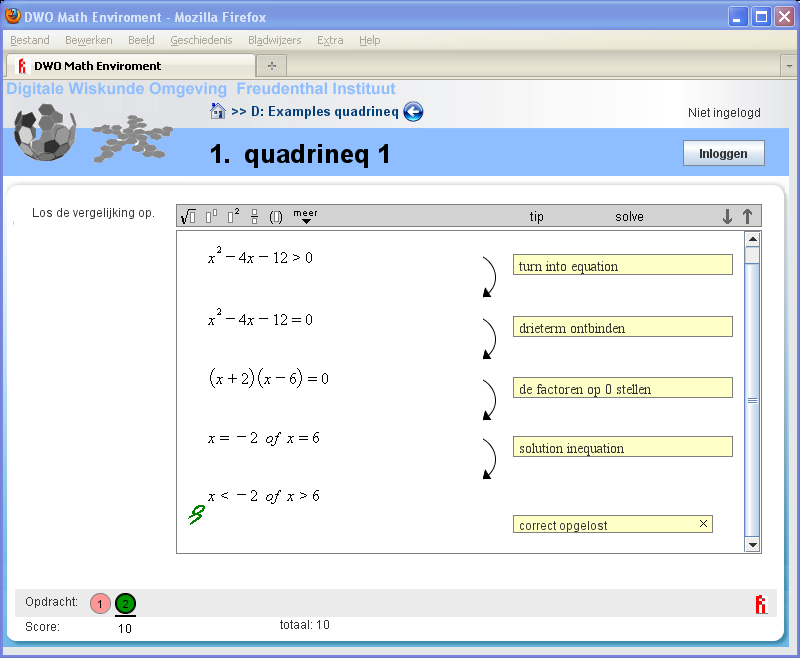
We are adding support for more exercise types, mainly at the level of high
school mathematics. For example, our tool now covers simplifying expressions
with exponents, rational equations, and derivatives. We have investigated how
users can interleave solving different parts of exercises. Recently, we have
focused on designing a
functional programming tutor. This tool lets you practice
introductory functional programming exercises. We are investigating how we can
add testing to the tutor, and how we can let teachers configure the tutor for
particular programming exercises.
This is ongoing research.
The feedback services are available as a
Cabal source package. The
latest release is version 1.0 from September 1, 2011.
Further reading
8.2 Data Management and Visualization
Pandoc aspires to be the swiss army knife of text markup formats: it
can read markdown and (with some limitations) HTML, LaTeX, Textile, and
reStructuredText, and it can write markdown, reStructuredText, HTML,
DocBook XML, OpenDocument XML, ODT, RTF, groff man, MediaWiki markup,
GNU Texinfo, LaTeX, ConTeXt, EPUB, Textile, Emacs org-mode,
Slidy, and S5. Pandoc’s markdown syntax includes extensions for LaTeX math,
tables, definition lists, footnotes, and more.
Since the last report, many new features have been added and improvements
made. Some highlights:
- Support for Textile input and output.
- Support for Emacs org-mode output.
- A new “builder” module for constructing Pandoc documents programatically.
- Support for LaTeXmath macros in markdown documents.
- Support for automatic citations and bibliographies using Andrea
Rossato’s citeproc-hs library.
These last two changes bring two of the most powerful features of LaTeX
to pandoc.
Further reading
http://johnmacfarlane.net/pandoc/
8.2.3 DSH — Database Supported Haskell

Database-Supported Haskell, DSH for short, is a Haskell library
for database-supported program execution. Using the DSH library, a
relational database management system (RDBMS) can be used as a
coprocessor for the Haskell programming language, especially for those
program fragments that carry out data-intensive and data-parallel
computations. Rather than embedding a relational language into Haskell,
DSH turns idiomatic Haskell programs into SQL queries. The DSH library
and the FerryCore package it uses are available on Hackage
(http://hackage.haskell.org/package/DSH).
DSH in the Real World.
We have used DSH for large scale data analysis. Specifically, in
collaboration with researchers working in social and economic sciences,
we used DSH to analyse the entire history of Wikipedia (terabytes of
data) and a number of online forum discussions (gigabytes of data).
Because of the scale of the data, it would be unthinkable to conduct the
data analysis in Haskell without using the database-supported program
execution technology featured in DSH. We have formulated several DSH
queries directly in SQL as well and found that the equivalent DSH
queries were much more concise, easier to write and maintain (mostly due
to DSH’s support for nesting, Haskell’s abstraction facilities and the
monad comprehension notation, see below).
One long-term goal is to allow researchers who are not necessarily expert programmers or database engineers to conduct large scale data analysis themselves.
Towards a New Compilation Strategy.
As of today, DSH relies on a query compilation strategy coined
loop-lifting. Loop-lifting comes with important and desirable
properties (e.g., the number of SQL queries issued for a given
DSH program only depends on the static type of the program’s
result). The strategy, however, relies on a rather complex and
monolithic mapping of programs to the relational algebra. To remedy
this, we are currently exploring a new strategy based on the
flattening transformation as conceived by Guy Blelloch.
Originally designed to implement the data-parallel declarative language
NESL, we revisit flattening in the context of query compilation (which
targets database kernels, one particular kind of data-parallel execution
environment). Initial results are promising and DSH might switch over in
the not too far future. We hope to further improve query quality and
also address the formal correctness of DSH’s program-to-queries mapping.
Related Work.
Motivated by DSH we reintroduced the monad comprehension notation
into GHC and also extended it for parallel and SQL-like comprehensions.
The extension is available in GHC 7.2.
Further reading
http://db.inf.uni-tuebingen.de/research/dsh
8.3 Functional Reactive Programming
Reactive-banana is a library for functional reactive programming (FRP). The goal is to create a solid foundation for anything FRP-related.
- Users can finally start experimenting with graphical user interfaces based on FRP as the library can be hooked into any existing event-based framework like wxHaskell or Gtk2Hs. A plethora of example code helps with getting started.
- Programmers interested in implementing FRP will have a reference for a simple semantics with a working implementation.
- It features an efficient implementation. No more spooky time leaks, predicting space &time usage should be straightforward.
Version 0.4.3 of the reactive-banana library has been released on Hackage. It provides a solid push-based implementation of a subset of the semantics for FRP pioneered by Conal Elliott. Compared to the previous report, interoperability with external event frameworks has been improved. The library now also provides many examples, as shown in the screenshot.
Current development focuses on a more integrated notion of time and dynamic event switching.
Further reading
8.3.2 Functional Hybrid Modelling
The goal of the FHM project is to gain a better foundational understanding of
noncausal, hybrid modelling and simulation languages for physical systems and
ultimately to improve on their capabilities. At present, our central research
vehicle to this end is the design and implementation of a new such language
centred around a small set of core notions that capture the essence of the
domain.
Causal modelling languages are closely related to synchronous data-flow
languages. They model system behaviour using ordinary differential equations
(ODEs) in explicit form. That is, cause-effect relationship between variables
must be explicitly specified by the modeller. In contrast, noncausal languages
model system behaviour using differential algebraic equations (DAEs) in
implicit form, without specifying their causality. Inferring causality from
usage context for simulation purposes is left to the compiler. The fact that
the causality can be left implicit makes modelling in a noncausal language
more declarative (the focus is on expressing the equations in a natural way,
not on how to express them to enable simulation) and also makes the models
much more reusable.
FHM is an approach to modelling which combines functional programming and
noncausal modelling. In particular, the FHM approach proposes modelling with
first class models (defined by continuous DAEs) using combinators for their
composition and discrete switching. The discrete switching combinators enable
modelling of hybrid systems (i.e., systems that exhibit both continuous and
discrete dynamic behaviour). The key concepts of FHM originate from work on
Functional Reactive Programming (FRP).
We are implementing Hydra, an FHM language, as a domain-specific language
embedded in Haskell. The method of embedding employs quasiquoting and enables
modellers to use the domain specific syntax in their models. The present
prototype implementation of Hydra enables modelling with first class models
and supports combinators for their composition and discrete switching.
We implemented support for dynamic switching among models that are computed at
the point when they are being “switched in”. Models that are computed at
run-time are just-in-time (JIT) compiled to efficient machine code. This
allows efficient simulation of structurally dynamic systems where the number
of structural configurations is large, unbounded or impossible to determine in
advance. This goes beyond to what current state-of-the-art noncausal modelling
languages can model. The implementation techniques that we developed should
benefit other modelling and simulation languages as well.
We are also exploring ways of utilising the type system to provide stronger
correctness guarantees and to provide more compile time reassurances that our
system of equations is not unsolvable. Properties such as equational balance
(ensuring that the number of equations and unknowns are balance) and ensuring
the solvability of locally scoped variables are among our goals. Furthermore,
a small core language for FHM is being developed and formalised in the
dependently-typed language Agda, allowing us to prove important properties,
such as the termination and productivity of the structural dynamics.
In July, this year, I submitted my PhD thesis featuring an in-depth
description of the design, semantics and implementation of the Hydra language.
In addition, the thesis features a range of example physical systems modelled
in Hydra. The examples are carefully chosen to showcase those language
features of Hydra that are lacking in other noncausal modelling languages. The
next release of Hydra is planned for December, this year. The release will
feature all examples from the thesis.
Further reading
The implementation of Hydra and related papers (including my PhD thesis) are
available from http://db.inf.uni-tuebingen.de/team/giorgidze.
Elerea (Eventless reactivity) is a tiny discrete time FRP
implementation without the notion of event-based switching and
sampling, with first-class signals (time-varying values). Reactivity
is provided through various higher-order constructs that also allow
the user to work with arbitrary time-varying structures containing
live signals.
Stateful signals can be safely generated at any time through a
specialised monad, while stateless combinators can be used in a purely
applicative style. Elerea signals can be defined recursively, and
external input is trivial to attach. The library comes in three major
variants, which all have precise denotational semantics:
- Simple: signals are plain discrete streams isomorphic
to functions over natural numbers;
- Param: adds a globally accessible input signal for
convenience;
- Clocked: adds the ability to freeze whole subnetworks
at will.
The code is readily available via cabal-install in the elerea
package. You are advised to install elerea-examples as well
to get an idea how to build non-trivial systems with it. The examples
are separated in order to minimize the dependencies of the core
library. The experimental branch is showcased by Dungeons of Wor,
found in the dow package (http://www.haskell.org/communities/05-2010/html/report.html#sect6.11.2). Additionally, the basic
idea behind the experimental branch is laid out in the WFLP 2010
article Efficient and Compositional Higher-Order Streams.
Since the last report, the Clocked variant of the library was
completely reimplemented. As opposed to the previous version, the new
implementation correctly executes according to the desired semantics,
and it is also more efficient.
Further reading
8.4 Audio and Graphics
8.4.1 Audio Signal Processing
In this project, audio signal algorithms are written in Haskell,
that is,
no binding to existing sound synthesis systems like SuperCollider. The highlights are:
- It is based on the Numeric Prelude framework (http://haskell.org/communities/05-2009/html/report.html#sect5.6.2).
- We support physical units while maintaining efficiency,
- There are frameworks for abstraction from sample rate.
That is, the sampling rate can be omitted in most parts
of a signal processing expression.
-
We checked several low-level implementations in order to achieve reasonable speed.
We complement the standard list type
with a lazy StorableVector structure
and a StateT s Maybe a generator, like in stream-fusion.
Now, both our custom signal generator type
and the Stream type from stream-fusion
can be fused to work directly on storable vectors.
-
There is support for causal processes.
Causal signal processes only depend on current and past data
and thus are suitable for real-time processing
(in contrast to a function like time reversal).
These processes are modeled as mapAccumL like functions.
Many important operations like function composition
maintain the causality property.
They are important
for sharing on a per sample basis
and in feedback loops
where they statically warrant that no future data is accessed.
- Type class framework for unifying lazy time values
and signals expressed by lists, storable vectors or signal generators.
- Connection to ALSA bindings, in order to provide real-time sound synthesis
controlled by MIDI events from keyboards or sequencers.
-
A real-time software synthesizer
that employs Just-In-Time-compilation and vector instructions
provided by the Low-Level Virtual Machine (http://llvm.org/)
Recent advances are:
- Allow to describe acyclic arrow networks using a functional notation.
By observation of sharing and the new Vault data structure
we get the same efficiency
as when using arrow combinators or the arrow syntax.
Further reading
8.4.2 Tidal, Texture and Live Music with Haskell
For a number of years, I have been improvising live music with Haskell.
I have made a pattern library called Tidal and have most recently been
working on an experimental visual language on front of that called
Texture (formerly known as Text, and I am still in the process of
renaming it). There are various videos and some more information on
my homepage.
I have been using Tidal and its predecessors in live performance for
some years, as shown this video of a
performance in Norway: http://piksel.blip.tv/file/4521577/. The quality of the recording is not perfect,
but it does show people dancing to Haskell. This performance was with
Dave Griffiths (who used his own
visual Scheme language SchemeBricks), we perform together (usually as
a trio with Adrian Ward) as Slub, and are
available for bookings.
Texture is rather experimental, but I recently ran a workshop with it,
and got six non-programmers writing Haskell code to improvised music
of the acid techno genre together over a few hours.
The code is available at http://darcs.slab.org/, but is
undocumented and difficult to get running. Those interested in
dabbling in this area would probably be better off looking at
hsc3 or
haskore.
Conductive
is another new and interesting library.
At the moment I am finishing off my PhD thesis on a related topic,
after that I intend to spend some time packaging Tidal and Texture
properly.
Folks interested in Haskell and music, as well as other artforms
should consider signing up to the
haskell art
mailing list.
Further reading
http://yaxu.org/
Hemkay (An M.K. Player Whose Name Starts with an H) is a simple music
module player that performs all the mixing in Haskell. It supports the
popular ProTracker format and some of its variations with different
numbers of channels. The device independent mixing functionality can
be found in the hemkay-core package.
The current version of the player uses the list-based PortAudio
bindings for playback, which is highly inefficient.
Since the last update, the mixer went through some performance
optimisations. However, the improved mixing performance can only be
exploited either through the alternative callback interface of
PortAudio (check the hemkay/callback branch on GitHub), or
through the OpenAL version (hemkay/openal branch). Out of
the two, the PortAudio version is significantly more efficient, but it
is prone to random crashes. Note that this alternative PortAudio
binding is only available on GitHub.
Further reading
8.4.4 Functional Modelling of Musical Harmony
Music theory has been essential in composing and performing music for centuries.
Within Western tonal music, from the early Baroque on to modern-day jazz and pop
music, the function of chords within a chord sequence can be explained by
harmony theory. Although Western tonal harmony theory is a thoroughly studied
area, formalising this theory is a hard problem.
We have developed a system, named HarmTrace, that
formalises the rules of tonal harmony as a Haskell
(generalized) algebraic datatype. Given a sequence of chord labels, the harmonic
function of a chord in its tonal context is automatically derived. For this, we
use several advanced functional programming techniques, such as
type-level computations, datatype-generic programming, and
error-correcting parsers. We have an
experience report at ICFP’11
detailing this project.
As an example, we show a tree representation of the harmony analysis of a short
music fragment:
A functional model of harmony offers various
benefits: for instance, it can help musicologists in batch-analysing large
corpora of digitised scores, but it has proven to be especially useful for
solving Music Information Retrieval (MIR) problems. MIR is the research field
that aims to provide methods that keep large collections of digital music
accessible and maintainable. Hence, besides generating musically meaningful
harmonic analyses, HarmTrace explores ways of exploiting these generated
analyses to improve the similarity assessment of chord sequences
and the automatic extraction for chord labels from musical audio. Some empirical
evidence showing that the harmonic analyses of HarmTrace improve harmonic
similarity estimation has been published at the
International Society for Music Information Retrieval conference 2011.
The code is also
available on Hackage.
Further reading
http://www.cs.uu.nl/wiki/GenericProgramming/HarmTrace
Cologne is a ray tracer being developed in Haskell. The goal is to produce a fun and relatively performant ray tracer. The project has been slowed down recently as my main focus has been on importing more complex models through the Assimp project (→7.7.1), but development should pick up this summer. Check out this render of the smallpt scene:

Further reading
https://github.com/joelburget/Cologne
8.5 Hardware Design
CλaSH (CAES Language for Synchronous Hardware) is a functional hardware description language that borrows both its syntax and semantics from Haskell.
The clock is implicit for the descriptions made in CλaSH: the behaviour of the circuit is described as transition from the current state to the next, which occurs every clock cycle.
The current state is an input of such a transition function, and the updated state part of its result tuple.
As descriptions are also valid Haskell, simulations can simply be performed by a Haskell compiler/interpreter (GHC only, due to the use of type families).
Instead of being an embedded language such as ForSyDe (http://www.haskell.org/communities/05-2010/html/report.html#sect6.8.1)
and Lava (→8.5.2)(→10.10), CλaSH has a compiler which can translate Haskell to synthesizable VHDL.
The compiler has support for, amongst others: polymorphism, higher-order functions, user-defined algebraic datatypes, and all of Haskell’s choice mechanisms.
The CλaSH compiler uses GHC for parsing, de-sugaring, and type-checking.
The resulting Core-language description is then transformed into a normal form, from which a translation to VHDL is direct.
The transformation system uses a set of rewrite rules which are exhaustively applied until a description is in normal form.
Examples of these rewrite rules are beta-reduction and eta-expansion, but also transformations to transform higher-order functions to first-order functions, and transformation for the specialization of polymorphic functions.
The CλaSH compiler was first presented to the community, after 7 months of work, at the Haskell 2009 symposium in Edinburgh, Scotland.
Support for arrows and the corresponding syntax, which eases the composition of transition functions, was added in July 2010 and was subsequently presented at IFL 2010 in Alphen a/d Rijn, The Netherlands.
The CλaSH compiler, available as a library, can be found both on Hackage (http://hackage.haskell.org/package/clash, stable) and github (http://github.com/christiaanb/clash/, development).
The compiler/interpreter is also available as an executable, which is basically the GHC binary extended with the CλaSH library, on the CλaSH website (http://clash.ewi.utwente.nl).
What is new?
There is now simulation and synthesis support for hardware descriptions that have multiple clock domains, starting with version 0.1.3.0 of CλaSH.
Example usage of multiple clock domains is explained here: http://www.haskell.org/pipermail/haskell-cafe/2011-March/090471.html.
The code for the demo (which uses multiple clock domains) we did at the DATE’11 conference is available here: http://github.com/christiaanb/DE1-Cyclone-II-FPGA-Board-Support-Package.
Further reading
http://clash.ewi.utwente.nl
Kansas Lava is a Domain Specific Language (DSL) for expressing
hardware descriptions of computations, and is hosted inside the
language Haskell. Kansas Lava programs are descriptions of specific hardware
entities, the connections between them, and other computational abstractions
that can compile down to these entities. Large circuits have been successfully
expressed using Kansas Lava, and Haskell’s powerful abstraction mechanisms, as
well as generic generative techniques, can be applied to good effect to provide
descriptions of highly efficient circuits.
Kansas Lava draws considerably from Xilinx Lava (http://www.haskell.org/communities/11-2010/html/report.html#sect3.7)
and
Chalmers Lava (→10.10).
The release of Kansas Lava, version 0.2.4, happened in early November.
Based round this release, there are a number of resources for users,
including a (draft) tutorial, and a youtube channel with
walkthroughs of our Lava in use.
On top of Kansas Lava, we are developing Kansas Lava Cores, which was released
on hackage at the same time as Kansas Lava. In hardware, a core is a component
that can be realized as a circuit, typically on an FPGA. Kansas Lava Cores
contains about a dozen cores, and basic board support for Spartan3e,
as well as an emulator for the Spartan3e.
Using various components provided as Kansas Lava Cores, we are developing the
λ-bridge (→8.8.2), with implementations in Haskell and
Kansas Lava of a simple protocol stack for communicating with FPGAs. We have
early prototypes working, and implementation in Kansas Lava continues.
Finally, we are working on a Lava idiom called a Patch, which is a Kansas
Lava component interface that uses types to declare protocols and handshakes
needed and used. Most of components in the Kansas Lava Cores are instances of
our Patch idiom. There is a PADL 2012 paper describing Patch,
including the design and implementation of a controller for an ST7066U-powered
LCD display.
Tristan Bull graduated in May 2011 with an MS. His MS thesis was about using
Kansas Lava. Congratulations Tristan!
Further reading
8.6 Proof Assistants and Reasoning
The Haskell Equational Reasoning Model-to-Implementation Tunnel
(HERMIT) is an NSF-funded project being run at KU (→10.11) to improving the
Applicability of Haskell-Hosted Semi-Formal Models to High Assurance
Development. Specifically, HERMIT will use the worker/wrapper
transformation, a Haskell-hosted DSL, and a new refinement UI to
perform rewrites directly on Haskell Core, the GHC internal
representation.
This project is a substantial case study into the application of
worker/wrapper on larger examples. In particular, we want to
demonstrate the equivalences between efficient Haskell programs, and
their clear, specification-style Haskell counterparts. In doing so,
there are several open problems, including refinement scripting and
management scaling issues, data representation and presentation
challenges, and understanding the theoretical boundaries of the
worker/wrapper transformation.
The project is currently being staffed up, and is
expected to run through 2013, and will be released
open-source in due time.
Further reading
http://www.ittc.ku.edu/csdl/fpg/Tools/HERMIT
8.6.2 Automated Termination Analyzer for Haskell
There
are many powerful techniques for automated termination analysis of
term rewriting.
However, up to now they have hardly been used for real programming
languages. We developed an approach which permits
the application of existing techniques from term rewriting to prove termination
of most functions defined in Haskell programs. In particular,
we show how termination techniques for ordinary rewriting can be used to handle
those features of Haskell which are missing in
term rewriting (e.g., lazy evaluation,
polymorphic types, and higher-order functions). We implemented our results in the
termination prover AProVE. When testing it on existing
standard Haskell-libraries, it turned out that AProVE
can fully automatically prove
termination of the vast majority of the functions in the libraries.
Further reading
8.6.3 Free Theorems for Haskell
Free theorems are statements about program behavior derived from (polymorphic)
types. Their origin is the polymorphic lambda-calculus, but they have also
been applied to programs in more realistic languages like Haskell. Since there
is a semantic gap between the original calculus and modern functional
languages, the underlying theory (of relational parametricity) needs to be
refined and extended. We aim to provide such new theoretical foundations, as
well as to apply the theoretical results to practical problems.
The research grant that sponsored Daniel’s position has been extended for another round of funding.
However, currently we are both consumed by teaching the (by local definition, imperative) programming intro course here at U Bonn, in C (yes, in C), plus an advanced functional programming course, in Haskell.
On the practical side,
we maintain a library and tools for generating free theorems from Haskell types, originally implemented by Sascha Böhme and with contributions from Joachim Breitner and now Matthias Bartsch. Both the library and a shell-based tool are available from Hackage (as free-theorems and ftshell, respectively). There is also a web-based tool at http://www-ps.iai.uni-bonn.de/ft/.
Features include:
-
three different language subsets to choose from
-
equational as well as inequational free theorems
-
relational free theorems as well as specializations down to function level
-
support for algebraic data types, type synonyms and renamings, type classes
-
plain text, LaTeX source, PDF, and inline graphics output with nicely typeset theorems
Further reading
http://www.iai.uni-bonn.de/~jv/project/
Swish is a framework for performing deductions in RDF data using a
variety of techniques. Swish is conceived as a toolkit for
experimenting with RDF inference, and for implementing stand-alone RDF
file processors (usable in similar style to CWM, but with a view to
being extensible in declarative style through added Haskell function
and data value declarations). It explores Haskell as “a scripting
language for the Semantic Web”, is a work-in-progress, and currently
incorporates:
-
Support for Turtle, Notation3, and NTriples formats.
-
RDF graph isomorphism testing and merging.
-
Display of differences between RDF graphs.
-
Inference operations in forward chaining, backward chaining and proof-checking modes.
-
Simple Horn-style rule implementations, extendable through variable binding modifiers and filters.
-
Class restriction rule implementation, primarily for datatype inferences.
-
RDF formal semantics entailment rule implementation.
-
Complete, ready-to-run, command-line and script-driven programs.
Current Work
A number of incremental changes have been made to the code base,
including support for version 7.2 of GHC and some minor
optimisations. A parser and formatter for the Turtle format were
added, the API changed to use the Text datatype where appropriate, and
the vocabulary module was extended to include terms from the Dublin
Core, FOAF, Geo and SIOC vocabularies.
Future plans
Continue the clean up and replacement of code with packages from
Hacakge. Look for commonalities with the other existing RDF Haskell package,
rdf4h.
Community input — whether it be patches, new code or just feature
requests — are more than welcome.
Further reading
8.7 Natural Language Processing
The Haskell Natural Language Processing community aims to make Haskell a
more useful and more popular language for NLP. The community provides a
mailing list, Wiki and hosting for source code repositories via the
Haskell community server.
The Haskell NLP community was founded in March 2009. The list is still
growing slowly as people grow increasingly interested in both natural
language processing, and in Haskell. Since the last report, there have
been several new releases in the community:
- brillig [Hackage]: Partial implementation of the Brill part of
speech tagging algorithm (see also the sequor package) (Eric Kow)
- tokenize [Hackage]: Simple tokenizer for English text (Grzegorz Chrupala)
- monad-atom [Hackage]: Monadically convert objects to unique atoms
and back (Grzegorz Chrupala)
- nlp-scores [Hackage]: Scoring functions commonly used for
evaluation in NLP and IR. Accuracy, Reciprocal Rank, Average Accuracy (Grzegorz Chrupala)
- Grammatical Framework: Programming with Multilingual
Grammars, Aarne Rante, CSLI Publications, Stanford, 2011, 340 pp,
ISBN-10: 1-57586-626-9 (Paper), 1-57586-627-7 (Cloth).
Also in development are the following packages
At the present, the mailing list is mainly used to make announcements to
the Haskell NLP community. Recently, there has been a small uptick in
activity, with users looking for NLP libraries on the mailing list. We
hope this will further expand and bindings that would be most useful to
us and ways of spreading awareness about Haskell in the NLP world.
Further reading
http://projects.haskell.org/nlp
GenI is a surface realizer for Tree Adjoining Grammars. Surface
realization can be seen a subtask of natural language generation
(producing natural language utterances, e.g., English texts, out of
abstract inputs). GenI in particular takes a Feature Based
Lexicalized Tree Adjoining Grammar and an
input semantics (a conjunction of first order terms), and produces the
set of sentences associated with the input semantics by the grammar. It
features a surface realization library, several optimizations, batch
generation mode, and a graphical debugger written in wxHaskell. It was
developed within the TALARIS project and is free software licensed under
the GNU GPL, with dual-licensing available for commercial purposes.
Work on GenI has begun anew. Since May 2011, Eric is working with
Computational Linguistics Ltd and SRI international to develop new
features for GenI and improve its scalability and performance for use in
an interactive tutoring application. We are excited to see GenI
potentially being used in the real world!
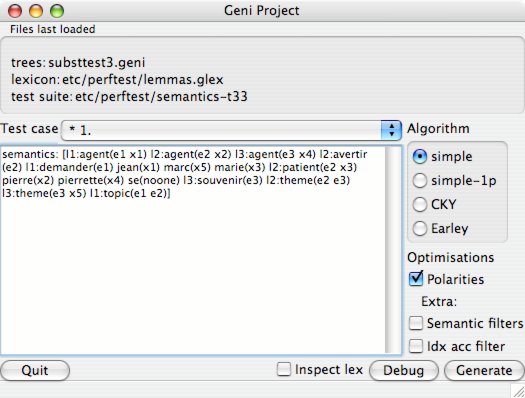
GenI is available on Hackage, and can be installed via cabal-install.
Our most recent release of GenI was version 0.20.2 (2009-12-02), with
some bugfixes and simplifications. For more information, please contact
us on the geni-users mailing list.
Further reading
8.8 Others
Feldspar is a domain-specific language for digital signal processing (DSP). The
language is embedded in Haskell and developed in co-operation by Ericsson,
Chalmers University of Technology (Göteborg, Sweden) and Eötvös Lorand
(ELTE) University (Budapest, Hungary).
The motivating application of Feldspar is telecoms processing, but the language
is intended to be useful for DSP in general. The aim is to allow DSP functions
to be written in functional style in order to raise the abstraction level of the
code and to enable more high-level optimizations. The current version consists
of an extensive library of numeric and array processing operations as well as a
code generator producing C code for running on embedded targets.
The current version deals with the data-intensive numeric algorithms which are
at the core of any DSP application. More recently, we have started to work on
extending the language to deal with more system-level aspects such as memory
layout and concurrency.
The implementation is available from Hackage.
Further reading
The λ-bridge effort provides enabling technology for using functional
programming on FPGA fabrics and boards. The majority of the artifacts are
shared documentation of ways to use FPGA board, and libraries (software and
hardware) that facilitate the use of FPGAs.
Techniques for programming FPGA boards are well documented, and there
are many online examples and other resources to draw from. Getting data to and
from a new hardware configuration, however, is a problem every bit (pun
intended) as challenging as programming a FPGA in the first place. From
empirical evidence, engineers that need communications with a host processor
write custom VHDL or Verilog for their specific board to solve this problem.
λ-bridge helps solve this problem.
We are using Kansas Lava (→8.5.2) to generate various “Cores” that provide
a network protocol stack centered
round the simple λ-bridge protocol, while being generic
about the physical layer.
For example, we support the RS-232 cable and UDP over ethernet,
and have plans for USB and (where applicable) directly via a motherboard bus.
The protocol is also implemented in Haskell, to provided the host-side
support.
Using the λ-bridge is not the fastest way of communicating
with a board, but we hope will be an easy way of getting up and running
with a design.
Between Kansas Lava, Kansas Lava Cores, and λ-bridge, we plan
to introduce a new generation of functional programmers to the joys
of FPGA programming.
We are especially interested in using λ-bridge to build
a bridge between the statistics language R, and FPGA board,
in an attempt to speed up some common statical operations
by offshoring the computation to FPGAs.
Further reading
http://www.ittc.ku.edu/csdl/fpg/Tools/LambdaBridge
8.8.3 GenProg — Genetic Programming Library
The GenProg library is a framework for genetic programming. Genetic
programming is an evolutionary technique, inspired by biological
evolution, to evolve programs for solving specific problems. A genetic
program is represented as an abstract syntax tree and associated with
a custom-defined fitness value indicating the quality of the solution.
Starting from a randomly generated initial population of genetic
programs, the genetic operators of selection, crossover, and
(occasionally) mutation are used to evolve programs of increasingly
better quality. Standard reference is John Koza’s Genetic
programming: On the Programming of Computers by Means of Natural
Selection.
In GenProg, a genetic program is represented by a value of an
algebraic datatype. To use a datatype as a genetic program, it
suffices to define it as an instance of the GenProg
typeclass. Any custom datatype can be made an instance of the
GenProg typeclass. In particular, to use instances of the
Data typeclass as genetic programs it suffices to define two
simple functions: one for the generation of random terminal nodes and
another for the generation of random nonterminal nodes. The evolution
is governed by several user defined parameters, such as population
size, crossover and mutation probabilities, termination criterion,
and mutation function. The package is available on Hackage.
Further reading
http://hackage.haskell.org/package/genprog
Manatee’s aim is to build a Haskell Operating System.
I am an Emacs fan (http://www.emacswiki.org/emacs/AndyStewart) that
uses Emacs everyday for everything.
But Emacs does not support multi-thread and is not safe enough.
So I am building my own Haskell integrated environment — Manatee.
You can write any application in it, and the Manatee framework will
mix your application with the current environment.
And, most importantly, it gives you a uniform experience with different
applications.
Framework
Manatee uses a multi-process framework that makes the extension
and the core running in separate processes to protect the application.
It will minimize your losses when some unexpected exception happens in the
current application; you just need to close/reload the current tab, any other
application and the core are still running safely.
Manatee uses a Model-View split design; you can split the current window to
get different views for the same buffer (a bit like Emacs’s buffers and
windows).
Then you can mix any applications together with this design for working efficiently.
Future plans
I have written the below applications in Manatee:
- Web Browser
- Download Manager
- Editor
- File Manager
- Image Viewer
- IRC Client
- Multimedia Player
- PDF Viewer
- Process Manager
- News Reader
- Terminal
More applications are in development, you are welcome to join us!
Further reading
Contact
- Mailing lists:
<manatee-user at googlegroups.com>,
<manatee-develop at googlegroups.com>
- IRC channel:
irc.freenode.net,
6667,
##manatee
XMonad is a tiling window manager for X. Windows are arranged
automatically to tile the screen without gaps or overlap, maximizing
screen use. Window manager features are accessible from the keyboard; a
mouse is optional. XMonad is written, configured, and extensible in
Haskell. Custom layout algorithms, key bindings, and other extensions may
be written by the user in config files. Layouts are applied
dynamically, and different layouts may be used on each workspace.
Xinerama is fully supported, allowing windows to be tiled on several
physical screens.
Development since the last report has continued; XMonad founder Don Stewart
has stepped down and Adam Vogt is the new maintainer.
After gestating for 2 years, version 0.10 has been released, with simultaneous
releases of the XMonadContrib library of customizations (which has now grown to
no less than 216 modules encompassing a dizzying array of features) and the
xmonad-extras package of extensions,
Details of changes between releases can be found in the release notes:
- http://haskell.org/haskellwiki/Xmonad/Notable_changes_since_0.8
- http://haskell.org/haskellwiki/Xmonad/Notable_changes_since_0.9
- the Darcs repositories have been upgraded to the hashed format
- XMonad.Config.PlainConfig allows writing configs in a more ’normal’ style, and not raw Haskell
- Supports using local modules in xmonad.hs; for example: to use definitions from ã/.xmonad/lib/XMonad/Stack/MyAdditions.hs
- xmonad –restart CLI option
- xmonad –replace CLI option
- XMonad.Prompt now has customizable keymaps
- Actions.GridSelect - a GUI menu for selecting windows or workspaces &substring search on window names
- Actions.OnScreen
- Extensions now can have state
- Actions.SpawnOn - uses state to spawn applications on the workspace the user was originally on,
and not where the user happens to be
- Markdown manpages and not man/troff
- XMonad.Layout.ImageButtonDecoration &
XMonad.Util.Image
- XMonad.Layout.Groups
- XMonad.Layout.ZoomRow
- XMonad.Layout.Renamed
- XMonad.Layout.Drawer
- XMonad.Layout.FullScreen
- XMonad.Hooks.ScreenCorners
- XMonad.Actions.DynamicWorkspaceOrder
- XMonad.Actions.WorkspaceNames
- XMonad.Actions.DynamicWorkspaceGroups
Binary packages of XMonad and XMonadContrib are available for all major Linux distributions.
Further reading

Bioinformatics in Haskell is a steadily growing field, and the
Bio section on Hackage now sports several libraries and
applications. The
biohaskell web site coordinates this
effort, and provides documentation and related information.
Anybody interested in the combination of Haskell and bioinformatics is encouraged
to sign up to the
mailing list.
Bioinformatics is a diverse field, and consequently, we have
different libraries covering
mostly separate areas.
This summer, some of us participated at the
BOSC codefest, and
we agreed to factor out common data types that other libraries could
use. The result is
biocore, currently
in revision 0.2. There is an ongoing effort to adapt existing
libraries to biocore.
The biolib library
that supports various sequence and alignment-oriented file formats and
operations, is now in the process of being deprecated. Functionality
is gradually being factored out, and this has so far resulted in
separate libraries for 454 sequencing reads (biosff), and PSL
alignment files (biopsl).
The Biobase-prefixed libraries provide basic functionality for a
number of data formats. A number of additional libraries are provided:
RNAfold is a partial port the ViennaRNA package, MC-Fold-DP: a
polynomial-time version of the original MC-Fold pipeline, while
RNAwolf provides a novel RNA-folding algorithm with non-canonical
secondary structures. On the level of non-coding RNA prediction,
CMCompare is used to assess the discriminatory power of RNA family
models.
The biostockholm
package supports parsing and pretty printing of files in Stockholm 1.0
format. These formats are used by Pfam
and Rfam for multiple sequence alignments.
Finally, there is
samtools wrapping the samtools C library for accessing and
manipulating BAM alignment files, and
seqloc providing functionality for manipulating sequence
locations and annotation.
Further reading
Bullet is a professional open source multi-threaded 3D Collision
Detection and Rigid Body Dynamics Library written in C++. It is free
for commercial use under the zlib license. The Haskell bindings ship
their own (auto-generated) C compatibility layer, so the library can be used without
modifications. The Haskell binding provides a low level API to access Bullet C++ class methods.
Some bullet classes (Vector, Quaternion, Matrix, Transform) have their own Haskell representation,
others are binded as class pointers. The Haskell API provides access to some advanced features, like
constraints, vehicle and more.
At the current state of the project most common services are accessible
from Haskell, i.e., you can load collision shapes and step the
simulation, define constraints, create raycast vehicle, etc.
More advanced Bullet features (soft body
simulation, Multithread and GPU constaint solver, etc.) will be added later.
Further reading
http://www.haskell.org/haskellwiki/Bullet
Sloth2D is a purely functional 2D physics library with composable
high-level abstractions. The primary intent behind this initiative is
not to compete with existing engines, but rather to experiment with
novel, composable abstractions for physics. This might eventually
lead to better high-level interfaces for existing engines, e.g., the
Chipmunk and Bullet bindings (→8.8.7). However, in the long run it might grow
into something that is usable in practice by itself.
The cabalised source is available on GitHub.
Current features:
- 100%pure implementation
- deterministic simulation (replayable regardless of sampling
rate)
- convex colliders
Planned features:
- other collider shapes: concave, round, half-plane
- collision layers
- spatial hashing for more efficient collision detection
- object deactivation
- support for raycasting
- serialisation of physics state
- combinators on dynamic worlds
- constraints
- friction
- stacking
- a scene graph-based interface to define the world in a compact
manner
Further reading
https://github.com/cobbpg/sloth2d
hledger is a library and end-user tool (with command-line, curses and web
interfaces) for converting, recording, and analyzing financial
transactions, using a simple human-editable plain text file format. It is
a haskell port and friendly fork of John Wiegley’s Ledger, licensed under
GNU GPLv3+.
hledger aims to be a reliable, practical tool for daily use. It reports
charts of accounts or account balances, filters transactions by type,
helps you record new transactions, converts CSV data from your bank,
publishes your text journal with a rich web interface, generates simple
charts, and provides an API for use in your own financial scripts and
apps.
In the last six months there have been two major releases. 0.15 focussed
on features and 0.16 focussed on quality. Changes include:
- new modal command-line interface, extensible with hledger-* executables in the path
- more useful web interface, with real account registers and basic charts
- hledger-web no longer needs to create support files, and uses latest yesod &warp
- more ledger compatibility
- misc command enhancements, API improvements, bug fixes, documentation updates
- lines of code increased by 3k to 8k
- project committers increased by 6 to 21
Current plans include:
- Continue the release rhythm of odd-numbered = features, even-numbered =
quality/stability/polish, and releasing on the first of a month
- In 0.17, clean up the storage layer, allow rcs integration via
filestore, and read (or convert) more formats
- Keep working towards wider usefulness, improving the web interface and
providing standard financial reports
Further reading
http://hledger.org
8.8.10 epub-tools (Command-line epub Utilities)
A suite of command-line utilities for creating and manipulating epub book files. Included are: epubmeta, epubname, epubzip.
epub-tools is available from Hackage, the Darcs repository below, and also in binary form for Arch Linux through the AUR.
Recent work has been centered on epubname and includes: Smarter parsing of dates in the OPF data, specifically for picking out publication date. The file naming architecture has been completely overhauled, is now more monadic and simpler. It’s much easier for a developer to add support for new magazines.
Further reading
9 Commercial Users
Well-Typed is a Haskell services company. We provide commercial support
for Haskell as a development platform, including consulting services,
training, and bespoke software development. For more information, please
take a look at our website or drop us an e-mail at
<info at well-typed.com>.
We are continuing to grow, with currently seven people working as full- or
part-time consultants. While we aren’t currently officially hiring, we are
still regularly looking for fresh blood, so if you would be interested working
for us, feel free to check in with us or send us your CV at any time.
We are working for a variety of commercial clients, but naturally, only some
of our projects are publically visible.
We continue to be involved in the support of GHC (→3.2). We have
contributed to the 7.2.1 release and are currently working towards the upcoming
7.4.1 release.
We coordinate and do work for the Industrial Haskell Group (IHG) (→9.3).
We have recently implemented a new dependency solver for Cabal and worked on
the Hackage server.
Within the Parallel GHC Project (→5.1.3), we continue to
help our old and new partners to implement parallel, concurrent and distributed
software in Haskell, and work to improve the tools and libraries, such as
ThreadScope.
In addition, we continue to be quite involved in the community, maintaining
several packages on Hackage. We have been present at the recent CamHac as well
as the Haskell in Leipzig meeting and of course ICFP, Haskell Symposium,
Haskell Implementors Workshop and CUFP. We have been teaching at the Utrecht
Summer School in Computer Science and the FPDay in Cambridge, and are involved
in the Oxford and Munich Haskell user groups.
Several events in the future are currently being planned, we will for example
speak at the FP eXchange in London on March 16, 2012, and we will certainly try
to participate in the next European Haskell Hackathon.
We are of course always looking for new clients and projects, too, so if you
are interested in hiring us, just drop us a mail.
Further reading
9.2 Bluespec Tools for Design of Complex Chips and Hardware Accelerators
Bluespec, Inc. provides an industrial-strength language (BSV) and
tools for high-level hardware design. Components designed with these
are shipping in some commercial smartphones and tablets today.
BSV is used for all aspects of ASIC and FPGA design — specification,
synthesis, modeling, and verification. All hardware behavior is
expressed using rewrite rules (Guarded Atomic Actions). BSV
borrows many ideas from Haskell — algebraic types, polymorphism,
type classes (overloading), and higher-order functions. Strong static
checking extends into correct expression of multiple clock domains,
and to gated clocks for power management. BSV is universally
applicable, from algorithmic “datapath” blocks to complex control
blocks such as processors, DMAs, interconnects, and caches.
Bluespec’s core tool synthesizes (compiles) BSV into high-quality
Verilog, which can be further synthesized into netlists for ASICs and
FPGAs using third-party tools. Atomic transactions enable
design-by-refinement, where an initial executable approximate design
is systematically transformed into a quality implementation by
successively adding functionality and architectural detail. The
synthesis tool is implemented in Haskell (well over 100K lines).
Bluesim is a fast simulation tool for BSV. There are extensive
libraries and infrastructure to make it easy to build FPGA-based
accelerators for compute-intensive software, including for the Xilinx
XUPv6 board popular in universities, and the Convey HC-1 high
performance computer.
BSV is also enabling the next generation of computer architecture
education and research. Students implement and explore architectural
models on FPGAs, whose speed permits evaluation using whole-system
software.
Status and availability
BSV tools, available since 2004, are in
use by several major semiconductor and electronic equipment companies, and universities. The
tools are free for academic teaching and research.
Further reading
Bluespec, a General-Purpose Approach to High-Level Synthesis
Based on Parallel Atomic Transactions, R.S. Nikhil, in High
Level Synthesis: from Algorithm to Digital Circuit, Philippe Coussy
and Adam Morawiec (editors), Springer, 2008, pp. 129-146.
-
BSV by Example, R.S. Nikhil and K. Czeck, 2010, book available on Amazon.com.
-
http://bluespec.com/SmallExamples/index.html: from BSV by Example.
-
http://www.cl.cam.ac.uk/~swm11/examples/bluespec/: Simon Moore’s BSV examples (U. Cambridge).
-
http://csg.csail.mit.edu/6.375: Complex Digital Systems, MIT courseware.
-
http://www.bluespec.com/products/BluDACu.htm: A fun example with many functional programming features — BluDACu, a
parameterized Bluespec hardware implementation of Sudoku.
9.3 Industrial Haskell Group
The Industrial Haskell Group (IHG) is an organization to support the
needs of commercial users of Haskell.
The main activity of the IHG is to fund work on the Haskell development
platform. It currently operates two schemes:
-
The collaborative development scheme pools resources from full members in order
to fund specific development projects to their mutual benefit.
-
Associate and academic members contribute to a separate fund which is used for
maintenance and development work that benefits the members and community in
general.
We welcome two new associate members to the IHG: Silkapp
(www.silkapp.com) and Pararallel Scientific.
In the past six months, the collaborative development scheme funded work
on cabal-install as well as improvements to the Hackage server. An intermediate
status report on the new dependency solver for cabal-install has been presented
at the Haskell Implementors Workshop. The solver is available for testing as
a branch in the Cabal repository and will soon be merged into the trunk.
Details of the tasks undertaken are appearing on the
Well-Typed (→9.1) blog and on the IHG status page.
The collaborative development scheme is running continuously, so
if you are interested in joining as a member, please get in touch.
Details of the different membership options (full, associate, or academic)
can be found on the website.
If you are interested in joining the IHG, or if you just have any comments,
please drop us an e-mail at <info at industry.haskell.org>.
Further reading

Tsuru Capital is engaged in high-frequency market-making on
options markets. Tsuru is a private company, and trades with its own
capital. Tsuru Capital currently runs arbitrage based liquidity
provision strategies on the Kospi 200 index and plans to expand to
Nikkei 225 index, and other electronic markets, over the next year.
The trading software has been developed entirely in Haskell, and
is one of the few systems in the world written completely in a
functional language.
Since 2010 we have opened our doors to students, post graduates,
and anyone looking for real world experience. And continue to do
so by offering paid 3 month internship positions every quarter.
Over the past year we have spent a good deal of time building GUIs
for our trading system, and tools for logging and playback. As a result
we have contributed bits and pieces of our work to Hackage, and will
continue to do so as we flesh out our framework.
Further reading
Barclays Capital has been using Haskell as the basis for our FPF (Functional Payout Framework) project for about six years now. The project develops a DSL and associated tools for describing and processing exotic equity options.
For the first half of its life the project focused only on the most exotic options — those which the legacy systems were unable to handle. Over the past few years however, FPF has expanded to provide the trade representation and tooling for the vast majority of our equity exotics and with that the team has grown significantly in both size and geographical distribution. We now have 10 full-time Haskell developers spread between New York, Hong Kong, Kiev and London (with the latter being the biggest development hub).
Our main language is a deeply embedded DSL which has proved very successful, but we are now reaching the stage where some of the traditional DSEL limitations (e.g., error messages and syntactical restrictions) have started to hinder its further adoption. As a result of this we are now working on a new, non-embedded, front-end FPF language which is based on stream arrows and we are investigating the possibility of using the Causal Commutative Arrows approach (Liu, Cheng, Hudak 2009). For the parsing part of this work we have been very impressed by Doaitse Swierstra’s uu-parsinglib (→7.2.3).
There are a number of other interesting projects going on within the team — these include a new C compiler (compiling our DSL into C) and performance improvement work as this has become more important as our trade population has grown. One interesting aspect of the new C compiler is that it has used an approach inspired by Rodriguez et al’s "Generic programming with fixed points for mutually recursive datatypes" to capture the internal AST in a flexible manner through the use of GADTs. (The majority of the rest of our codebase uses standard ADTs but in an unfixed form which facilitates traversals using standard catamorphisms, paramorphisms, apomorphisms etc.).
We have been and remain very satisfied GHC users and feel that it would have been significantly harder to develop our systems in any other current language.

Oblomov Systems is a one-person software company based in Utrecht, The Netherlands. Founded in 2009 for the Proxima 2.0 project (http://www.haskell.org/communities/05-2010/html/report.html#sect6.4.5), Oblomov has since then been working on a number of Haskell-related projects. The main focus lies on web-applications and (web-based) editors. Haskell has turned out to be extremely useful for implementing web servers that communicate with JavaScript clients or iPhone apps.
Awaiting the acceptance of Haskell by the world at large, Oblomov Systems also offers software solutions in Java, Objective C, and C#, as well as on the iPhone/iPad. Currently, Oblomov Systems is working together with Ordina NV on a substantial Haskell project for the Council for the Judiciary in The Netherlands.
Further reading
http://www.oblomov.com
10 Research and User Groups
10.1 A French community for Haskell

During the past few months, we have seen many new Haskellers in the French-speaking communities. Aside from this, Valentin Robert has published
a translation of Learn You a Haskell For Great Good in French (see the further reading section). It seems Haskell is finally getting more interest from French
developers and that is the reason why we are now trying to create some activity around this.
We are currently working on the basics:
- getting an adequate wiki/website,
- figuring out some project ideas, may they be documentation or software projects,
- working on a first French Hackathon event for French Haskellers to meet and get to know each other.
Among us, we happen to have people interested in many areas (Haskell for web programming, high performance Haskell, etc.) so on the long-term we may
be able to provide resources about various topics. Another possible idea would be to have some kind of workgroups that would work on a given project,
or even do bug hunting for an already existing project. And we have many other ideas, but it will depend on how the community’s activity grows.
Our priorities are the website and the first Hackathon, that may happen in June in Strasbourg. This is yet to be confirmed.
We warmly welcome anyone interested in helping us create this community! There are all kinds of tasks to accomplish so you do not need to be a Haskell guru to
contribute. We also welcome any French-speaking haskellers or even functional programmers to join us either on the IRC channel #haskell-fr on
Freenode or on the mailing list.
Further reading
10.2 Haskell at Eötvös Lorand University (ELTE), Budapest

Education
There are many different courses on Haskell and Agda are run at
Eötvös Lorand University, Faculty of Informatics.
-
Programming for first-year BSc students using Haskell, it is officially
in the curriculum.
-
Advanced functional programming using Haskell, it is an optional course
for BSc and MSc students.
-
Programming in Agda as an optional course for BSc and MSc students.
-
Other Haskell-related courses on Lambda Calculus, Type Theory and
Implementation of Functional Languages.
There is an interactive online evaluation and testing system, called
ActiveHs. It contains several hundred systematized exercises and it may
be also used as a teaching aid. There is also some experimenting going
on about supporting SVG graphics, and extending the embedded interpreter
and testing environment with safe emulation of IO values. ActiveHs is
now also avaiable on Hackage.
We started to work on translating our course materials to English,
because we are planning to use it for teaching foreign students in the
coming years.
This year we organized the Central European Functional Programming
Summer School again with more than 60 students. There were many
professional lectures delivered by experts on functional programming,
like Simon Marlow, Andrew Butterfield, Rinus Plasmeijer, or Mary
Sheeran.
Research
We have some research projects in functional programming that use
Haskell.
-
Feldspar, a high-level domain-specific language for digital signal
processing developed for Ericsson in cooperation with Chalmers
University of Technology. Our task is to implement an efficient
multi-platform ISO C99 code generator for the language.
-
Software Technologies for Distributed and Manycore Systems started in
2010. The Project is supported by the European Union and co-financed by
the European Social Fund.
Further reading
10.3 Functional Programming at UFMG and UFOP
The Functional Programming groups at Universidade Federal de Minas
Gerais and Universidade Federal de Ouro Preto are working on projects
that include the following ones:
Proposal for a Solution to Haskell’s Multi-parameter Type Class DilemmaThe proposal consists of using a simple satisfiability trigger
condition: check satisfiability if and only if there exists an
unreachable variable in a constraint.
This eliminates the need for functional dependencies (and any other
additional mechanism in the language) to tackle ambiguity and
overloading resolution.
E-mail messages about the proposal exchanged in Haskell-cafe and
Haskell-prime have not been constructive. The discussion in
Haskell-cafe deviated to what we see as an ortogonal issue, of
import and export of instances (see more about this in the
next paragraph).
So unfortunately the proposal has not been incorporated in Haskell
yet. A paper about it has been published at SBLP’2009 (see below).
We have implemented the proposal in a proptotype Haskell front-end
(https://github.com/rodrigogribeiro/core), and are currently
working on this front-end so that it can type all existing Haskell
libraries (that use multi-parameter type classes and higher-rank
polymorphism).
Controlling the scope of instances in HaskellMarco Gontijo is about to finish his MSc dissertation on the subject.
This is a simple and natural change that makes module export and
import free of treating instances as a special case. It also allows
alternative instances of a class for the same type to be defined and
used in different module scopes of a program, eliminates not only
problems related to the existence of orphan instances but also the
pollution of the global scope by unused instances.
An article about this has been published at SBLP’2011 (see
below). Marco Gontijo is currently implementing the proposal,
in our Haskell compiler prototype
(https://github.com/rodrigogribeiro/core); if time permits, also
in GHC.
Decidable type inference for Haskell overloading
When types have constraints, decidability of type inference is based
mainly on decidability of constraint set satisfiability. We have
designed a termination criterion for Haskell’s type inference
algorithm that deals with all the “complicated cases” (given in
e.g. the PPDP’04 and ACM TOPLAS 2005 references below).
A paper about this is being (re)written. An implementation is
available at https://github.com/rodrigogribeiro/core.
First Class Overloading and Intersection TypesA paper about this has been published at SBLP’2011 (see below).
The work is currently being implemented in our compiler front-end,
available at https://github.com/rodrigogribeiro/core.
The Hindley-Milner type system imposes the restriction that function
parameters must have monomorphic types. Lifting this restriction and
providing system F “first class” polymorphism is clearly desirable,
but comes with the difficulty that complete type inference for
higher-rank type systems is undecidable. More practical systems
supporting higher-rank types have been proposed, which rely on system
F, and require appropriate type annotations for the definition of
functions with polymorphic type parameters. But these type annotations
do inevitably disallow some possible uses of defined higher-rank
functions. To avoid this problem, we propose the annotation of
intersection types for specifying the types of function parameters
used polymorphically inside a function body.
Future work involves extending this work to allow also annotation of
union types, supporting then the use (manipulation) of heterogeneous
data structures by means of overloaded functions.
Further reading
-
A Solution to Haskell’s Multi-paramemeter Type Class Dilemma,
Carlos Camarão, Rodrigo Ribeiro, Lucilia Figueiredo,
Cristiano Vasconcellos, SBLP’2009 (13th Brazilian Symposium on
Programming Languages). http://www.dcc.ufmg.br/~camarao/CT/solution-to-mptc-dilemma.pdf
-
Controlling the Scope of Instances in Haskell,
Marco Silva, Carlos Camarão,
SBLP’2011 (15th Brazilian Symposium on Programming Languages).
http://www.dcc.ufmg.br/~camarao/controlling-the-scope-of-instances-in-Haskell-sblp2011.pdf
-
Constraint-set satisfiability for Overloading, Carlos
Camarão, Lucilia Figueiredo, Cristiano Vasconcellos, ACM
Press Conf. Proceedings of PPDP’04 , 67–77,
2004. http://www.dcc.ufmg.br/~camarao/CT/cs-sat/cssat.pdf
-
A theory of overloading, Peter J. Stuckey, Martin Sulzmann,
ACM TOPLAS 2005, 27(6),
1216–1269. http://portal.acm.org/citation.cfm?id=1108974
-
First Class Overloading via Intersection Type Parameters,
Elton Maximo Cardoso, Carlos Camarão, Lucilia Figueiredo,
SBLP’2011 (15th Brazilian Symposium on Programming Languages).
http://www.dcc.ufmg.br/~camarao/CT/intersection-type-parameters.pdf
10.4 Artificial Intelligence and Software Technology at Goethe-University Frankfurt
Programming language semantics. One of our research topics focuses on programming language semantics,
especially on contextual equivalence
which is usually based on the operational semantics of the language.
Deterministic call-by-need lambda calculi with letrec provide a semantics for the core language of Haskell.
For such an extended lambda calculus we proved correctness of strictness analysis using abstract reduction,
and we proved equivalence of the call-by-name and call-by-need semantics. Recently we have shown that
applicative bisimilarity is complete w.r.t. contextual equivalence in this calculus.
We also explored several nondeterministic extensions of call-by-need lambda calculi and their applications.
A recent result is that for calculi with letrec and nondeterminism usual
definitions of applicative similarity are unsound w.r.t. contextual equivalence.
We analyzed a higher-order functional language
with concurrent threads, monadic IO and synchronizing variables as a core language of Concurrent Haskell.
To assure declarativeness of concurrent programming we extended the language
by implicit, monadic, and concurrent futures. Using contextual equivalence based on may- and should-convergence,
we have shown that various transformations preserve program equivalence,
e.g. the monad laws hold in our calculus. Most recently we have shown that the language with concurrency
conservatively extends the pure core language of Haskell, i.e. all program equivalences for the pure part also hold in the
concurrent language.
In a recent research project we try to automate correctness proofs of program transformations.
These proofs require to analyze the overlappings between reductions of the operational semantics
and transformation steps by computing so-called forking and commuting diagrams.
Recently we implemented an algorithm as a combination of several unification algorithms in Haskell
which computes these diagrams. Ongoing research is to automate the corresponding induction proofs
(which use the diagrams) using automated termination provers for term rewriting systems.
Grammar based compression. Another research topic of our group focuses on algorithms on grammar compressed strings and trees.
One goal is to reconstruct known algorithms on strings and terms (unification, matching, rewriting etc.)
for their use on grammars without prior decompression. We recently developed an algorithm for computing the
congruence closure on grammar compressed terms. We implemented several algorithms in Haskell which are
available as a Cabal package.
Further reading
http://www.ki.informatik.uni-frankfurt.de/research/HCAR.html
10.5 Functional Programming at the University of Kent
The Functional Programming group at Kent is a subgroup of the Programming Languages and Systems Group of the School of Computing.
We are a group of staff and students with shared
interests in functional programming. While our work is not limited to
Haskell — in particular our interest in Erlang has been growing —
Haskell provides a major focus and common language for teaching
and research.
Our members pursue a variety of Haskell-related projects, some of
which are reported in other sections of this report.
The third edition of Simon Thompson’s text book Haskell: the craft of functional programming appeared in June 2011.
Thomas Schilling presented his work on improving type error messages for GHC at TFP 2011 and his work on trace-based dynamic optimisations for Haskell programs at IFL 2011.
Olaf Chitil is working on more expressive lazy assertions for Haskell.
Further reading
10.6 Formal Methods at DFKI and University Bremen
The activities of our group center on formal methods, covering a
variety of formal languages and also translations and heterogeneous
combinations of these.
We are using the Glasgow Haskell Compiler and many of its extensions
to develop the Heterogeneous tool set (Hets). Hets consists of
parsers, static analyzers, and proof tools for languages from the CASL
family, such as the Common Algebraic Specification Language (CASL)
itself (which provides many-sorted first-order logic with partiality,
subsorting and induction), HasCASL, CoCASL, CspCASL, and ModalCASL.
Other languages supported include Haskell (via Programatica), QBF,
Maude, VSE, TPTP, THF, OWL, Common Logic, FPL (logic of
functional programs) and LF type theory. The Hets implementation is
also based on some old Haskell sources such as bindings to uDrawGraph
(formerly Davinci) and Tcl/TK that we maintain. Apart from a Gtk2Hs
user interface hets also provides many functionalities as a web server
based on warp (→5.2.2).
HasCASL is a general-purpose higher-order language which is in particular
suited for the specification and development of functional programs; Hets also
contains a translation from an executable HasCASL subset to Haskell. There is
a prototypical translation of a subset of Haskell to Isabelle/HOL.
The Coalgebraic Logic Satisfiability Solver CoLoSS is being implemented
jointly at DFKI Bremen and at the Department of Computing, Imperial
College London. The tool is generic over representations of the syntax and
semantics of certain modal logics; it uses the Haskell class mechanism,
including multi-parameter type classes with functional dependencies,
extensively to handle the generic aspects.
Further reading
10.7 Haskell at Universiteit Gent, Belgium
Haskell is one of the main research topics of the new Programming Languages Group at the
Department of Applied Mathematics and Computer Science at the University of Ghent, Belgium.
Teaching
UGent is a great place for Haskell-aficionados:
-
As of this academic year, make Haskell part of your curriculum with our
brand new Functional and Logic Programming Languages course.
-
Explore Haskell in depth with one of our Haskell master thesis topics.
-
Attend the thriving Ghent Functional Programming Group (→10.14).
Research
Haskell-related projects of the group members and collaborators are:
-
Search Combinators:
Search heuristics often make all the difference between effectively solving a
combinatorial problem and utter failure. Hence, the ability to swiftly design
search heuristics that are tailored towards a problem domain is essential to
performance improvement. In other words, this calls for a high-level
domain-specific language (DSL).
The tough technical challenge we face when designing a DSL for search
heuristics, is to bridge the gap between a conceptually simple specification
language (high-level, purely functional and naturally compositional) and an
efficient implementation (typically low-level, imperative and highly
non-modular). We overcome this challenge with a systematic approach in Haskell
that disentangles different primitive concepts into separate monadic modular
mixin components, each of which corresponds to a feature in the high-level DSL.
The great advantage of mixin components to provide a semantics for our DSL is
its modular extensibility.
This is joint work with Guido Tack, Pieter Wuille, Horst Samulowitz and Peter
Stuckey, following up on Monadic Constraint Programming, a monadic DSL
for Constraint Programming in Haskell.
-
Monads, Zippers and Views: Virtualizing the Monad Stack:
We make monadic components more reusable and robust to changes by employing two
new techniques for virtualizing the monad stack: the monad
zipper and monad views. The monad zipper is a higher-order monad
transformer that creates virtual monad stacks by ignoring particular layers in
a concrete stack. Monad views provide a general framework for monad stack
virtualization: they take the monad zipper one step further and integrate it
with a wide range of other virtualizations. For instance, particular views
allow restricted access to monads in the stack. Furthermore, monad views
provide components with a call-by-reference-like mechanism for
accessing particular layers of the monad stack. With our two new mechanisms,
the monadic effects required by components no longer need to be literally
reflected in the concrete monad stack. This makes these components more
reusable and robust to changes.
This is joint work with Bruno Oliveira, part of which is available together with Mauro
Jaskelioff’s monad transformer library in the Monatron package on Hackage.
-
EffectiveAdvice:
EffectiveAdvice is a disciplined model of (AOP-style) advice, inspired by
Aldrich’s Open Modules, that has full support for effects in both base
components and advice. EffectiveAdvice is implemented as a Haskell library.
Advice is modeled by mixin inheritance and effects are modeled by monads.
Interference patterns previously identified in the literature are expressed as
combinators. Equivalence of advice, as well as base components, can be checked
by equational reasoning. Parametricity, together with the combinators, is used
to prove two harmless advice theorems. The result is an effective model of
advice that supports effects in both advice and base components, and allows
these effects to be separated with strong non-interference guarantees, or
merged as needed. This is joint work with Bruno Oliveira and William Cook.
Further reading
This is to report some activities of the Ro/Haskell Group. The Ro/Haskell page becomes more and more known as time goes. Actually, the Ro/Haskell Group is officially a project of the Faculty of Sciences, “V. Alecsandri” Univ. of Bacãau, Romania (http://stiinte.ub.ro) based by volunteers.
During the academic year 2011 – 2012 the "Gentle Introduction to Haskell 98" was translated in Romanian and was published by MatrixRom Publishing House (http://www.matrixrom.ro). Romanian title : "O mica introducere in Haskell 98". Prof Paul Hudak had offered a forward for Romanian users.
Website:
On the 7th of Oct. 2011, the main Ro/Haskell’s web page counter recorded the total of almost 40 000 times accessed. Some pages was added, included one dedicate to the above book and some pages dedicated to the Leksah IDE. (http://leksah.org)
Books:
The book “The Practice Of Monadic Interpretation” by Dan Popa had been published in November 2008. The book had developed into a full PhD. thesis which was successfully defended in public in September 2010. No English version is available so far.
Actually the Official Publishing House of the Ro/Haskell Group is MatrixRom (www.matrixrom.ro).
Speaking of books, the “Gentle introduction to Haskell” was prepared this year and was on the market in a Romanian translation. The introductory chapter (http://www.haskell.org/wikiupload/3/38/Gentle_1-19-v06-3Aprilie.pdf.zip) can be downloaded from http://www.haskell.org/haskellwiki/Gentle where two other versions are available, too: French and of course English.
“An Introduction to Haskell by Examples” is now out of print but if you need, a special pack can be provided based on the agreement of the author <popavdan at yahoo.com>. Also available on special request from PIM Publishing House, in Iasi.
Products:
Haskell products like Rodin (a small DSL a bit like C but written in Romanian) begin to spread, proving the power of the Haskell language. The Pseudocode Language Rodin is used as a tool for teaching basics of Computer Science in some high-schools from various cities. Rodin was asked to become a FOSS (Free &Open Source Software) and will be. To have a sort of C using native keywords was a success in teaching basics of Computer Science: algorithms and structured programming.
Linguists:
A group of researchers from the field of linguistics located at the State Univ. from Bacãau (The LOGOS Group) is declaring the intention of bridging the gap between semiotics, high level linguistics, structuralism, nonverbal communication, dance semiotics (and some other intercultural subjects) and Computational Linguistics (meaning Pragmatics, Semantics, Syntax, Lexicology, etc.) using Haskell as a tool for real projects. Probably the situation from Romania is not well known: Romania is probably one of those countries where computational linguistics is studied by computer scientists less than linguists. We had begun by publishing an article about The Rodin Project in order to attract linguists.
We are trying to extend the base of available books in libraries.
At Bacãau “V. Alecsandri” University
We have teaching Haskell at two Faculties: Sciences (The Computers Science being included) and we hope we will work with Haskell with the TI students from the Fac. of Engineering, where a course on Formal Languages was requested.
At Brasov “Transilvania” University
The book "An Introduction to Haskell by Examples" was requested by teachers from the "Transilvania" Univ. of Brasov., where a master course on functional programming in Haskell was introduced.
Notions:
We are promoting new notions: pseudoconstructors over monadic values (which act both as semantic representations and syntactic structure), modular trees (expanding trees beyound the fixity of the data declarations) and ADFA — adaptive/adaptable determinist finite automata. A dictionary of new notions and concepts is not made, making difficult to launch new ideas and also to track work of the authors.
Unsolved problems:
PhD. advisors (specialized in monads, language engineering, and Haskell) are almost impossible to find. This fact seems to block somehow the hiring of good specialists in Haskell. Also it is difficult to track the Haskell related activity from various universities, like those from: Sibiu, Baia Mare, Timisoara. Please report them using the below address.
Contact
<popavdan at yahoo.com>
Further reading
10.9 fp-syd: Functional Programming in Sydney, Australia
We are a seminar and social group for people in Sydney, Australia,
interested in Functional Programming and related fields. Members of
the group include users of Haskell, Ocaml, LISP, Scala, F#, Scheme
and others. We have 10 meetings per year (Feb–Nov) and meet on the
third Thursday of each month. We regularly get 20–30 attendees, with
a 70/30 industry/research split. Talks this year have included material
on Category Theory, theorem proving, type systems, Template Haskell and a
couple of different Haskell libraries. We usually have about 90 mins of
talks, starting at 6:30pm, then go for drinks afterwards. All welcome.
Further reading
10.10 Functional Programming at Chalmers
Functional Programming is an important component of the Department of
Computer Science and Engineering at Chalmers. In particular, Haskell
has a very important place, as it is used as the vehicle for teaching
and numerous projects. Besides functional programming, language
technology, and in particular domain specific languages is a common
aspect in our projects.
The FP group has two new PostDocs: Moa Johansson and Meng Wang. Moa works
on automated reasoning about recursive programs and Meng works on
random generation of typed terms.
We have a just started a new 5-year project called “RAW FP:
Productivity and Performance through Resource Aware Functional
Programming”.
Property-based testingQuickCheck is the basis for a European Union project on Property Based
Testing (www.protest-project.eu). We are applying the QuickCheck
approach to Erlang software, together with Ericsson, Quviq, and
others. Much recent work has focused on PULSE, the ProTest User-Level
Scheduler for Erlang, which has been used to find race conditions in
industrial software — see our ICFP 2009 paper for details. A new tool,
QuickSpec, generates algebraic specifications for an API
automatically, in the form of equations verified by random testing.
We have published about it at TAP 2010; an earlier paper can be found here:
http://www.cse.chalmers.se/~nicsma/quickspec.pdf. Lastly, we have
devised a technique to speed up testing of polymorphic properties:
http://publications.lib.chalmers.se/cpl/record/index.xsql?pubid=99387.
Natural language technologyGrammatical Framework (http://www.haskell.org/communities/11-2010/html/report.html#sect9.7.3)
is a declarative language for describing
natural language grammars. It is useful in various applications
ranging from natural language generation, parsing and translation to
software localization. The framework provides a library of large
coverage grammars for currently fifteen languages from which the
developers could derive smaller grammars specific for the semantics of
a particular application.
Parser generator and template-haskellBNFC-meta is an
embedded
parser generator, presented at the Haskell Symposium 2011. Like the
BNF Converter, it generates a compiler front end in Haskell. Two
things separate BNFC-meta from BNFC and other parser generators:
- BNFC-meta is not a program but a library (the parser description
is embedded in a quasi-quote).
- BNFC-meta automatically provides quasi-quotes for the specified
language. This includes a powerful and flexible facility for
antiquotation.
More info:
http://hackage.haskell.org/package/BNFC-meta.
Generic ProgrammingStarting with Polytypic Programming in 1995 there is a long history of
generic programming research at Chalmers. Recent developments include
fundamental work on
“Proofs
for Free” (extensions of the parametricity &dependent types work
from ICFP 2010), a Haskell Symposium paper on
“Embedded
Parser Generators” (see BNFC-meta above) and a workshop on
“DSLs
for Economical and Environmental Modelling”. Patrik Jansson leads
a work-package on DSLs within the EU project “Global Systems Dynamics
and Policy” (http://www.gsdp.eu/, started Oct. 2010). If you
want to apply DSLs, Haskell, and Agda to help modelling global
sustainability challenges, please get in touch!
Language-based securitySecLib is a light-weight library to provide security policies for
Haskell programs. The library provides means to preserve
confidentiality of data (i.e., secret information is not leaked) as
well as the ability to express intended releases of information known
as declassification. Besides confidentiality policies, the library
also supports another important aspect of security: integrity of data.
SecLib provides an attractive, intuitive, and simple setting to
explore the security policies needed by real programs.
Type theoryType theory is strongly connected to functional programming research.
Many dependently-typed programming languages and type-based proof
assistants have been developed at Chalmers. The Agda system (→4.1) is the
latest in this line, and is of particular interest to Haskell
programmers. We encourage you to experiment with programs and proofs
in Agda as a “dependently typed Haskell”.
Embedded domain-specific languagesThe functional programming group has developed several different domain-specific languages embedded in Haskell. The active ones are:
- Feldspar (→8.8.1) is a domain-specific language
for digital signal processing (DSP), developed in co-operation by
Ericsson, Chalmers FP group and Eötvös Lorand (ELTE)
University in Budapest.
- Obsidian is a language for data-parallel programming
targeting GPGPUs.
The following languages are not actively developed at the moment:
- Lava is a language for structural hardware
description. Circuits are modeled as ordinary Haskell functions, and
many of Haskell’s advantages (such as higher-order functions and
polymorphism) are also available for Lava descriptions. There are
several versions of Lava around. The version developed at Chalmers
aims particularly at supporting formal verification in a convenient
way.
- Wired is an extension to Lava, targeting (not exclusively) semi-custom VLSI design. A particular aim of Wired is to give the designer more control over on-chip wires’ effects on performance. The most recent activity was to use Wired to explore the layout of multipliers (Kasyab P. Subramaniyan, Emil Axelsson, Mary Sheeran and Per Larsson-Edefors. Layout Exploration of Geometrically Accurate Arithmetic Circuits. Proceedings of IEEE International Conference of Electronics, Circuits and Systems. 2009).
Home page: http://www.cse.chalmers.se/~emax/wired/.
Automated reasoningEquinox is an automated theorem prover for pure first-order logic with
equality. Equinox actually implements a hierarchy of logics, realized
as a stack of theorem provers that use abstraction refinement to talk
with each other. In the bottom sits an efficient SAT solver. Paradox
is a finite-domain model finder for pure first-order logic with
equality. Paradox is a MACE-style model finder, which means that it
translates a first-order problem into a sequence of SAT problems,
which are solved by a SAT solver. Infinox is an automated tool for
analyzing first-order logic problems, aimed at showing finite
unsatisfiability, i.e., the absence of models with finite domains. All
three tools are developed in Haskell.
TeachingHaskell is present in the curriculum as early as the first year of the
Bachelors program. We have three courses solely dedicated to
functional programming (of which two are Masters-level courses), but
we also provide courses which use Haskell for teaching other aspects
of computer science, such as programming languages, compiler
construction, hardware description and verification, data structures
and programming paradigms.
During 2012 the FP group will develop (and teach) a new MSc level
course on “Parallel Functional Programming”.
10.11 Functional Programming at KU

Functional Programming remains active at KU and
the Computer Systems Design Laboratory in ITTC.
The System Level Design Group (lead by Perry Alexander)
and the Functional Programming Group (lead by Andy Gill)
together form the core functional programming initiative at KU.
Apart from Kansas Lava (→8.5.2), ChalkBoard (→7.7.6),
Lambda Bridge (→8.8.2) and HERMIT (→8.6.1),
there are several other
FP and Haskell related things going on.
- We are continuing our development of a lightweight Haskell version of HOL.
Traditionally, members of the higher-order logic theorem (HOL) proving family
have been implemented in the Standard ML programming language or one of its
derivatives. HaskHOL aims to break with tradition by implementing a lightweight
HOL theorem prover library as a Haskell hosted domain specific language. Based
on the HOL Light logical system, HaskHOL aims to provide the ability for Haskell
users to reason about their code directly without having to transform it or
otherwise export it to an external tool. For details talk to Evan Austin.
- We are developing a library in Haskell for processing Rosetta
specifications. A current focus is the modularity and re-use of distinct
processing elements, such as type-checking, partial evaluation, and reasoning
assistants. Mutually defined elements that are more convenient to consider as
distinct interact via a reactive monadic computation, so the two elements’ code
can be managed as separate packages. Also, our principal specification
representation use functors and type-level fixed points to achieve extensibility
and generic programming. The goal of the library is to provide to a tight and
graduated interface to the basic processing elements, so that the users may
incorporate the most appropriate basic elements when implementing their own,
more domain-specific Rosetta processors. For details talk to Nick Frisby.
Further reading
10.13 San Simon Haskell Community
The San Simon Haskell Community from San Simon University Cochabamba-Bolivia,
is an informal Spanish group that aspire to learn, share information, knowledge
and experience related to the functional paradigm.
Our main activity is the development of projects, we have some projects in our Web
Page (http://comunidadhaskell.org) that serves us as a medium of communication and work environment.
Our last activity was the Local Haskell Hackathon that was held on April 8, 9 and 10
in our University. There were 15 participants of different levels in functional programming.
We have been working on projects idbjava (decompiler bytecode java), lexer and parser for Ruby,
emulator for CNC machine, and some Haskell games.
We have had a wonderful time of 2 days of programming, and I want to thank Vladimir
Costas and Pablo Azero for their assistence in the realization of this event.
The next thing we are waiting on is the 2nd Open House Haskell community where we will
show some of the projects we are working on.
I want to encourage all Spanish Haskell programmers to meet us on Facebook.
Further reading
http://comunidadhaskell.org
10.14 Ghent Functional Programming Group

The Ghent Functional Programming Group is a user group aiming to bring together programmers, academics, and others interested in functional programming located in the area of Ghent, Belgium.
Our goal is to have regular meetings with talks on functional programming, organize functional programming related events such as hackathons, and to promote functional programming in Ghent by giving after-hours tutorials.
The first seven GhentFPG meetings and BelHac were reported on in the previous HCARs.
Since then we have held two other GhentFPG meetings. GhentFPG #8, held in June 2011,
was a combination of talks and a problem-solving activity, where we pickled our brains
on a problem from the ACM World Finals Programming Contest.
GhentFPG #9 was a regular meeting with one normal talk and three lightning talks:
- Jurrien Stutterheim — Snaplets: composable and reusable web components.
- Andy Georges — hCole-server (lightning talk).
- Kenneth Hoste — GA: a genetic algorithm library (lightning talk).
- Jasper Van der Jeugt — WebSockets (lightning talk).
If you want more information on GhentFPG you can follow us on twitter
(@ghentfpg), via Google Groups
(http://groups.google.com/group/ghent-fpg), or by visiting us at
irc.freenode.net in channel #ghentfpg.
Further reading
http://groups.google.com/group/ghent-fpg

 consists of four λ turned in such a way that they form the Eden instantiation operator #05.
Higher-level coordination is achieved by defining
skeletons, ranging from a simple parallel map to sophisticated
master-worker schemes. They have been used to parallelize a set of
non-trivial programs.
consists of four λ turned in such a way that they form the Eden instantiation operator #05.
Higher-level coordination is achieved by defining
skeletons, ranging from a simple parallel map to sophisticated
master-worker schemes. They have been used to parallelize a set of
non-trivial programs.